Home Sweet Home
A place to feel safe!
Home Sweet Home
A place to feel safe!
(Org 2 Web Site – Too late for a headline; just the best I can do for now)
Just another org to hugo jekyll whatever guide? Guess again. But you also may read first. Exe-cute-if some-hurry: How to utilize org publish for a modern Website layout, including template and integrated css production; with a helping hand from R.
The motivation for this work was to reproduce and exercise the publishing features of org mode. The objective turned from information architecture into taming Web technology for public interests.
| This is a volatile expansion of [20]. You may post comments there and refer to the volatile expansion of 2022-08-02. I tried to avoid repetition, unless I turned inline links to bibliography citations. |
The tangible result of this expansion is still a static web site without javascript,1 based on html5 and something that might be called css3.2 The deployment is aimed at content delivery network, cdn, hosting of static sites. And now it is accessible by an url with the restriction of volatility; see Section 11 for the volatile connotation.
It is still hard to sort out all the detours and excursions; and to justify temporary simplifications. In the long version I rather report on some of the many aspects of Web technology approaches instead of a clean how-to with a straight line of conduct. I consider the result as my own lookup source for further work on free software solutions, beginning with a free publishing suite. And I publish it because sharing is the new having.
The research started with Sebastian Rose's worg entry
Publishing Org-Mode Files to HTML at orgmode.org
[22] and a comparison to Dennis Ogbe's approach
discussed in the blog entry Blogging using exclusively org-mode at
ogbe.net [16]. A lot of additional insight is from the
doc strings of the publishing functions, which are mainly part of
📂 ox-publish.el but also spread all over the individual
export libraries, especially 📂 ox-html.el. There are
duncan.codes andcasouri.github.io.The exercise quickly raised a lot of questions about content management and information architecture. These questions were the basis of the hypothesis that org mode has everything to combine into the tasks of a cms. Collaboration and system management, imho, should be outsourced to special software like trello and git.
For me even the “simple” project in the org Manual offers too many variations to act as an introductory showcase for org publishing. Nevertheless it's the only point of entry, so be prepared to get confused. As an anti confusion agent I offer a sketch of my “proceedings.”
The next bulk of sections explains and expands the corresponding
sections in the carpenter's Web site assimilation [20],
while Section 9 is a commented link to the
untouched section of the short version at pjs64.wordpress.com. In
contrast to [20] the loop mode for Sections 3 to 7 is extended to and includes the
deployment. And the order of the items is not an issue anymore; it's
just kept for reference to the condensed wordpress
preview.
Then I'm returning to my test-1-2 rookie Web site and apply the new skills of a static template constructor to generate a differently structured Web site. It was built to get the article you're looking at into a the next step on the way to a proper Web site and provide another workflow framework.
I produced my first basic set of test files from the attempt to develop plain org html exports which look very sober; see Figure 1.

The contents are from the capture chapter of the org mode Manual. The pages show some structural elements of Web pages: content, header, navigation, topics. Obviously they don't look like a wordpress blog. They lack Web site structure, layout and real design: a site header, navigation slots, some additional information in optional right or left columns or boxes, a footer.
Usually that's one of the tasks of a well developed content management
system. My hypothesis from the Intro: org mode offers
every feature to act as a cms. And I thought if
org's publishing procedure should do anything useful it
should at least be able to convert files into a complete Web site; see
the commentary in 📂 ox-publish.el, cited below in
Section 3. But Web sites reflect a site structure not a
page collection.
By employing some of org's publishing and export features I began to differentiate expectation from coded methods. A coarse introduction to org publish should set the scene for the first building brick.
The commentary of 📂 ox-publish.el tells us that “this
program allows configurable publishing of related sets of org mode files as a complete website.” It can
The statement “publishing is configured almost entirely through
setting the value of one variable, called org-publish-project-alist”
leaves the user with the uncertainty of “almost.” First of all
publishing means org mode publishing. And the
corresponding configuration implies an alist of this restricted
publishing model, only. But it handles dependencies to the whole
org mode empire. The org-publish-project-alist is not
a value, it's an association list, and it can be a pretty large one;
see Ogbe's blog entry cited in the Intro. The manual Section Project
Alist offers two syntactic patterns: the pattern of the lines one and
two, and the pattern of line three:
("postings" :property1 value1 :property2 value2) ("static-files" :property3 value3 :property4 value4) ("web-site" :components ("postings" "static-files"))
The third line defines web-site as a set of the sub-projects
postings and static-files. The sub-projects are called components;
they combine files requiring the same publishing procedures. When we
publish such a meta-project, all the components are also published,
in the given order. One of the publishing commands for the code above is
M-x org-publish-project RET web-site RET
A project consisting only of the first two lines' syntax is shown in
the Manual's Section Example: simple publishing configuration. This
example publishes a set of org files to the
📂 ~/public_html directory on the local machine. But it uses
a pain-in-the-ass attribute: simple. There's nothing simple about
this example, it's just restricted to the first syntax model and it's
kind of short. Even in the simple project we have to be aware of
all export and publish switches. imho that's very far
from simple. The simple example is
(setq org-publish-project-alist '(("org" :base-directory "~/org/" :publishing-function org-html-publish-to-html :publishing-directory "~/public_html" :section-numbers nil :with-toc nil :html-head "<link rel=\"stylesheet\" href=\"../other/mystyle.css\" type=\"text/css\"/>")))
The mandatory properties are
:base-directory – the folder containing publishing sources. All
files meeting the criteria defined by the properties described in
the Manual's Section Selecting Files are published according to
Section Publishing Action.:publishing-directory – target folder or tramp
syntax for published files.
Another necessary property is the :publishing-function, but it has a
default, so it might not be called mandatory3
:publishing-function is, by default, set to
org-html-publish-to-html
For the other three properties I offer a very short insight into configurations of the default html export:
:section-numbers nil – switches off the numbers for the headings:with-toc nil – switches off the table of contents, which would
be put beneath the title; title is the first entry of the export
<body> if :with-title is switched on. Without title the
table of contents is first.:html-head – the usage of :html-head is restricted to a part
of the export <head>. The whole <head> consists of a date comment, one
constructor of <meta> elements, another big one for head elements
like <style>, and of mathjax info. The big one is
addressed by :html-head; see the org-html-template in
📂 ox-html.el for the whole composition, sketched in
Section 5.2.
That was too much information. But at least I can figure out that for
my purpose the html export collection about org mode capture, Figure 1, will miss the point. With
these exports I don't get a clue about Web sites. In the Example
Selection of the short version at pjs64.wordpress.com I begin with
the German html Intro (→ google Translation),
accompanied by a showcase (→ gooTrl), at wiki.selfhtml.org.4 The Section 12.2.3
discusses the statement about the wiki.selfhtml.org supplements being
declared as public domain, CC0.
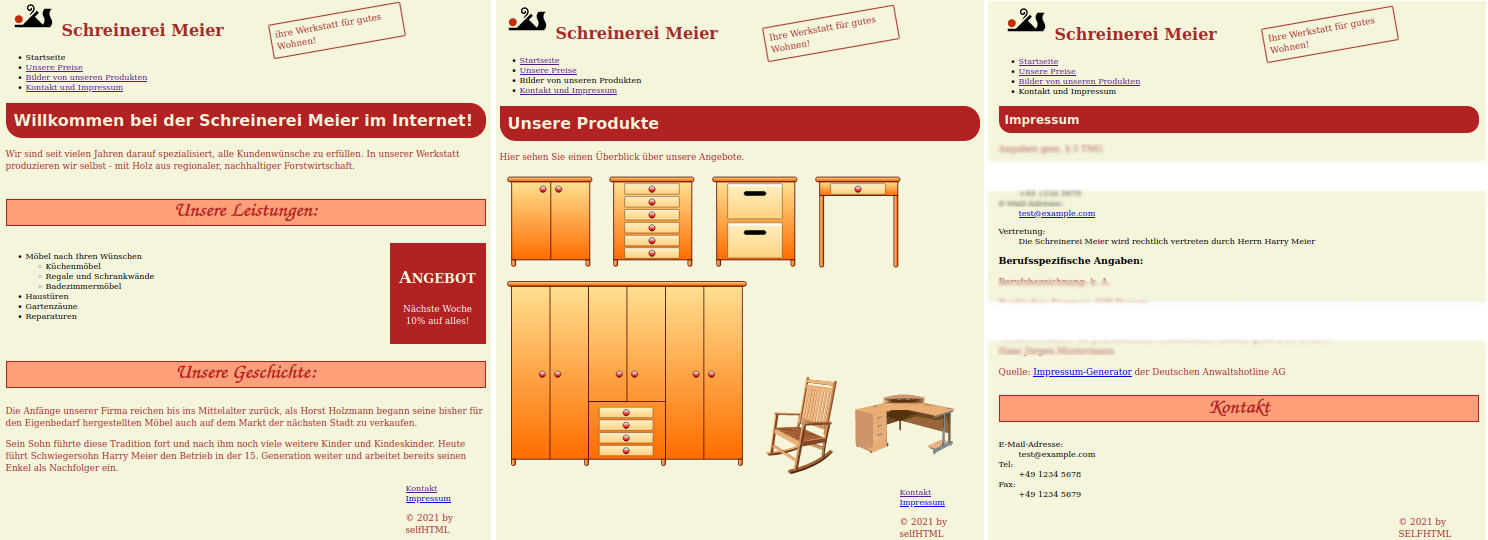
index.html, 📂 products.html, and a cut version of 📂 contact.html. Note the smaller font size of Impressum headline in the right page.All the additional layout material at the wiki entry (→ gT) CSS - fertige Layouts differs in design, only; though the name “css complete layouts”, not “complete Web site architectures.” So for the structural approach I envisioned in Section 2 I won't get a satisfying solution, but it turned out to be the entry for my cms hypothesis. The original file structure of the html Intro (→ google Translation), is
./ : index.html • inhalt.html • kontakt.html •
preise.html
css/ : formate.css • hobel.svg
img/ : some svg and jpg imagesvideo/ : carpentry.mp4
Now I take a step back and revisit the knowledge I earned from joomla about template design [23] and my typo3 research about the typoscript language dedicated to template scripting and its current template focus called fluid template. Combined with a three month seminar about management systems this previous knowledge puts me in a position to dissect the test site without destroying the workflow of the scientific workplace5 I planned to set up for Web technology experiments beginning with …
In my working environment the transferred and renamed original
html files get the sub-folder 📂 sthm0O,
i.e., 0O for nil–original, in my publishing root
📂 ~/www. It contains symbolic 📂 css/ and
📂 img/ folders and the four files
shtm0O/: index.html • products.html • contact.html
• pricing.html
Then I pandoc these html files to org, e.g.,
pandoc -f html -t org -o index.org index.html
and copy the org files into a sub-folder of my org file root
myOrgRoot/pub/shtm0/ : index.org • products.org •
contact.org • pricing.org
I prepare another sub-folder 📂 shtm0/ in my publishing
root 📂 ~/www. Here I add real 📂 css/ and
📂 img/ folders which are supposed to be filled with
I want to have all my pictures at one location only, my
picture root; this is something like 📂 ~/Pictures. I'm
referring to it with symbolic links. So I can access it from
latex files in custom folders, from org
folders, from html files, whatever. I want to keep this
structure of the picture root sub-folders for the uploaded online
files, too. For the example I create the sub-folder
📂 shtm0/. In the case of the small carpentry web site
example I departed from this principle and put all files into
📂 shtm0/, no subsubfolders.
After exporting the org page main content and embedding
the resulting html files into the template the media
will be collected into the 📂 ./img/ directory of the
web site. An xml crawler will have looked up the all
the images which are actually used in the html files of
the 📂 ~/www/shtm0/ folder.
~/www/shtm0/css/ and end up in the
📂 ./css/ folder of the Web site.The goal of this section is to investigate the publishing process and to identify cornerstones of possible org publish configurations. Well, and to get ideas about constructing the real Web sites to come. And then come up with the most basic configuration, which some people tend to call simple.
This is kind of a fake order. I don't org-publish
the pandoc'ed org files from above but the
files I already modified to get the right input for the templates,
developed in Section Website Template. |
The experimental setup of the elisp code for
discovering org-publish-project-alist begins with
(setq org-publish-project-alist '(("shtm0" :base-directory "~/myOrgRoot/pub/shtm0/" :publishing-directory "~/www/shtm0/" :publishing-function org-html-publish-to-html )))
For the short version of org2shtm I kept this code in the file
📂 shtm0.el for maintenance.6 Then I produced a
couple of publication scenarios described in the listing below and
picked the 📂 index.html files for comparison.
When evaluated the code creates a publishing project called shtm0
which can be invoked by M-x org-publish-project [RET] shtm0 or M-x
org-publish [RET] shtm0. The :publishing function exports all
org files in the :base-directory to html
files in the :publishing-directory. The first four files are the
result of producing two doc-types html5 (H5) and
xhtml (which is the default, so I call it Hd) with and
without <head>. The :body-only files are marked with a trailing
y.
index.html export to 📂 indexHd.html
📂 indexH5.html is the renamed result of adding
:html-doctype "html5" :html-container "section"
the headless html of 📂 indexH5y.html
is made with an additional
:body-only t
indexHdy.html is the same without the
:html-doctype and the :html-container.The org Manual for versions above 9.2 reports about seven switches to get a bare html, i.e., a minimal html file, with no css, no javascript, no preamble or postamble, but with a complete doctype-html-head-body structure; see Section Exporting to minimal HTML in the org Manual.
(setq org-html-head "" org-html-head-extra "" org-html-head-include-default-style nil org-html-head-include-scripts nil org-html-preamble nil org-html-postamble nil org-html-use-infojs nil)
The corresponding org-publish-project-alist notation of the
publishing properties looks similar;
:html-head "" :html-head-extra "" :html-head-include-default-style nil :html-head-include-scripts nil :html-preamble nil :html-postamble nil :html-use-infojs nil
According to this info I add two bare index file versions marked by
a trailing r: 📂 indexHdr.html and
📂 indexH5r.html, respectively.
Table 1 summarizes the set of the six experimental files
📂 indexH5.html, 📂 indexH5r.html,
📂 indexH5y.html, 📂 indexHd.html,
📂 indexHdr.html, and 📂 indexHdy.html.
| format | with-head | bare | body-only |
|---|---|---|---|
| xhtml | Hd | Hdr | Hdy |
| html5 | H5 | H5r | H5y |
In the first run the most interesting results were the :body-only
versions because I considered them to deliver the main content.
Comparing 📂 indexH5y.html and
📂 indexH5.html I found that :body-only t removes the
<!DOCTYPE html> element,<html lang="de">,<head> and<h1> brace for the title and its surrounding <div id="content">
brace in the <body>
Comparing 📂 indexHd.html and
📂 indexH5.html I observed that <h1> was embraced in a
<header> element for the html5 version. The abbreviated version
of 📂 indexH5.html shows these elements.
<!DOCTYPE html> <html lang="de"> <head> ... </head> <body> <div id="content"> <header><h1 class="title"> ... </h1></header> <!-- left out content beginning with a section element --> </div> </body> </html>
For all building blocks here's a coarse summary of the
org-html-template from 📂 ox-html.el. The comments
contain references to corresponding variables or publishing
properties.
<!-- xml- or php-declaration --> <!DOCTYPE html> <!-- choose from org-html-doctype-alist --> <html lang="de"> <!-- build <html> element language info --> <head> ... </head> <!-- date-comment, meta, head, mathjax info --> <body> <!-- :html-link-up :html-link-home :html-home/up-format --> <!-- org-html--build-preamble --> <div id="content"> <!-- read =org-html-divs= --> <header> <!-- a html5 feature --> <h1 class="title"> ... </h1> <!-- depends on :with-title --> </header> <!-- still a html5 feature --> <!-- left out content beginning with a section element --> </div> <!-- org-html--build-postamble --> <!-- insert html-klipsify-src --> </body> </html>
The title which is injected by the org-html--build-meta-info into the
<head> brace doesn't depend on the :with-title switch. By the way,
another difference of the :body-only export is that the id attributes of the
additional outline container <div>'s have different hash tags. For
example, the added outline <div> of a <h3> header looks like
<div id="outline-container-orgab9da8b" class="outline-3"> <h3 id="unsere-leistungen">Unsere Leistungen:</h3> <div class="outline-text-3" id="text-unsere-leistungen">
In this code block I call the sequence ab9da8b the hash tag of the
<div>'s id="outline-container-orgab9da8b" attribute. This side
effect might come in handy for customized css without
analyzing the whole export procedure for the html
body. Especially the fact that the hash tags get un-hashed by defining
a custom_id property for the corresponding section; see the
org Manual's Section Properties and Columns.
The most intriguing result of the experiments is that :body-only in
an html export is not only a <body> issue. But I'm
fairly happy with my minimal set of publishing options which are shown
in the code below, which I put into 📂 shtm0.el
available in the bitbucket repository, and revisited in Section 7.
(setq org-publish-project-alist '(("shtm0" :base-directory "~/myOrgRoot/pub/shtm0/" :publishing-directory "~/www/shtm0/" :publishing-function org-html-publish-to-html :body-only t :html-doctype "html5" :html-container "section" )))
The detailed description of the experimental setup
in this section is for further investigations of all switches which
affect the <body>. For all exports, general or html
specific. In the short version I only need to notice that the
html5 decision is a source of wide spread effects. E.g.,
both the preamble and postamble switches produce a <div> element in
the <body>, but not in the :body-only version. For inspiration I
will get into (1) :options-alist of org-export-define-backend in
📂 ox-html.el and (2) org-export-options-alist in
📂 ox.el. |
Back to the transferred and renamed semi-original html
files in 📂 ~/sthm0O. They are the source for identifying
locations in the html code where I might place the main
content, the navigational elements, the footer, or a menu.
The pages of the example Web site are very similar, so the header, the
navigation and the footer might be considered static. And I won't make
a big mistake if I decide to inject only the main content. Figure
2 shows three pages of the exercise layout showcase
(→ gooTrl) at the German wiki.selfhtml.org. In the caption the file
names are my customizations of the structure I declared above, but
they are linked to the original files.
“Considered to be static” means that the <header> is really
static: it consists of an icon, the company name, and
a rotated commercial message. The navigation is a plain7 list of links. The footer of all but the contact
pages contains links to the contact page and its imprint section.
Another minor irregularity regards the first line of what I will use
as the main content. All main contents begin with an <h1>
element. But in the contact page the <h1> element is embedded in an
<article> element and its font size is smaller. To figure out the
reason for this behavior I sketched the coarse structure of the main
content in the <body> of all pages – neglecting the <header>,
<nav>, and <footer> elements; see Table 2.
| index | contact | products | pricing |
|---|---|---|---|
<h1> |
<article> |
<h1> |
<h1> |
<p> |
• <h1>
|
<p> |
<table> |
<section> |
• <p>
|
<p> |
|
• <h2>
|
• 2 <dl>'s |
• 7 <img>'s |
|
• <ul>
|
• <h3>
|
||
• <aside>
|
• 9 <p>'s |
||
• • <h3>
|
<aside> |
||
• • <p>
|
• <h2>
|
||
<section> |
• <dl>
|
||
• <h2>
|
|||
• 2 <p>'s |
The contact appears kind of rough. <h1> and <h3> are on the same
level. The <aside> element isn't used. The font-size for the <h1>
element isn't specified explicitly in the corresponding
css file 📂 formate.css. Degrading to a
lower level by being embedded in another element seems to cause an
implicit font-size loss. The Design 01 (→ gT) layout at
selfhtml.org offers another version of this contacts page.
Well, to be complete, I also considered the page title to be static;
this is the title that shows up in the browser's tab register. In the
layout original the titles of the pages are different. Browser tab
titles are defined in the html <head>.
For the home page I want to produce the html code below
with a headerless html export from the file
📂 index.org in the publication folder
📂 pub/ of my org file root
<h1>Willkommen ...</h1> <p>Wir sind seit ....</p> <section id="service"> <h2>Unsere Leistungen:</h2> ... </section>
The template for every page of the example web site is the rest derived from the index file with the considerations above.
<!doctype html> <html lang="de"> <head> ... </head> <body> <header> ... </header> <nav> ... </nav> <!-- here's where the main content should be injected --> <footer> ... </footer> </body> </html>
I declare this to be the template; I'll add it as
📂 tmplt.html to the bitbucket supplements
and put the two parts above, below, and without the
main-content-comment as 📂 tmplt1.html and
📂 tmplt2.html into the publishing folder
📂 pub/shtm0 of 📂 ~/myOrgRoot/. Before
proceeding to the css I'll have to know how the export
fills in.
Exporting an org file to html offers a lot
of features, which are reflected in a lot of publishing switches for
html. And the publishing empire in turn produces many
additional opportunities for help, inspiration, and distraction. First
I'll investigate on the file based options for the header of my
📂 index.org file which is supposed to substitute the main
content placeholder in the template.
The lines beginning with #+8 in an org file
escape the text mode to some kind of control mode which translates to
in-buffer-settings or export settings, for example. Typing #+ in a
new line and asking for completion with M-[TAB]9 shows all available setting keywords.
The following #+ settings in the org file header are
for the test suite. Later some of them are transferred into the
project's org-publish-project-alist entry. But that depends on the
nature of each option. For example, #+Language: de is related to the
individual file, so it should stay in the file. While #+Options:
num:nil toc:nil depends on the web site architecture, so they might
end up in the publishing alist as :section-numbers nil or
:with-toc nil; see the end of Section 3.
The org code of the in-buffer #+HTML_CONTAINER: section
property transfers to the elisp code publishing property
:html-container "section". We can derive this connection by looking
up the in-buffer property at the Manual's Section HTML Specific
export settings and inspect the doc-string of the corresponding M-x h
org-html-container-element. Or look up the whole collection of
property relations in the backend definition of
📂 ox-html.el, i.e., the :options-alist of
org-export-define-backend.
Apart from entries like #+Title:, #+Subtitle:, #+Author:, or
#+Email: the settings for the carpenter's site are
#+Language: de #+Options: num:nil toc:nil #+HTML_CONTAINER: section #+HTML_DOCTYPE: html5
I assume the #+Language: to affect the body, so I'll keep it. I'll
set the num and toc attributes of #+Options: to abandon header
numbering and the table of contents, respectively; see the general
Export Settings. The #+HTML_DOCTYPE setting seems useless for the
body-only export. While the corresponding element isn't inserted, it
affects the usage of html5 elements in the body. The
#+HTML_CONTAINER: determines the next level beyond the <body>
element; this level adds an element bracket for the whole content; see
HTML Specific Export Settings in the Manual.
The Manual's Section html preamble and
postamble can be another source of inspiration for producing the main
content. See the docstring of C-h o
org-html-postamble-format. Unfortunately they are skipped for
body-only exports. |
The #+HTML_DOCTYPE: (see the Manual) triggers different conversions
of special elements like <aside> which is used in the index
page;10 see the Angebot panel in the left part
of Figure 2 and the <aside> placement in Table
2. The org code to produce this element is
#+Attr_html: :id offer #+begin_aside #+Html: <h3>Angebot</h3> Nächste Woche 10% auf alles! #+end_aside
The first line of the block below shows the enclosing elements for
regular conversion, the second line is the html5 version
<div id="offer" class="aside"> .. </div> <aside id="offer"> .. </aside>
The #+HTML_CONTAINER: section (see the Manual's Section HTML
doctypes) has two relevant effects. The usage in the org
header puts the whole document body into a <section> brace. Here the
difference of the xhtml default and html5 is
<div id="outline-container-org7bdb0cc" class="outline-2"> <section id="outline-container-org79ac04b" class="outline-2">
Another possible usage is related to the last paragraph of the
Manual's Section HTML doctypes: “Special blocks cannot have
headlines. For the html exporter to wrap the headline
and its contents in <section> or <article> tags, set the
HTML_CONTAINER property for the headline.” The offer <aside> could
be org coded like
*** Angebot :PROPERTIES: :HTML_CONTAINER: aside :CUSTOM_ID: offer :END: Nächste Woche 10% auf alles!
And it would be exported as the html snippet below;
another advantage: for the latex, and any other export
it would produce a regular subsubsection, not an aside environment
which I would have to define otherwise. But it gets more difficult to
address the css background property for this <aside>
element.
<aside id="outline-container-org70aac58" class="outline-4"> <h4 id="offer">Angebot</h4> <div class="outline-text-4" id="text-offer"> <p>Nächste Woche 10% auf alles!</p> </div> </aside>
In the preceding sections I produced an 📂 index.org
file for the main content of my home page. Now I can compare the
differences between export and intended main content; I'll call them
ex-main and in-main.
the whole ex-main is enclosed in
<section id="outline-container-org60ba67b" class="outline-2"> .. </section>
the heading tags include the id attribute of the PROPERTIES
drawer's CUSTOM_ID: field. I didn't include the drawers myself;
they were planted there by pandoc'ing the example
html files to org markup.
<h3 id="unsere-geschichte">Unsere Geschichte:</h3>
This also encourages the usage of custom ID's for proper linkage.
every header is followed by another <div> enclosing the text of
the section
<div class="outline-text-3" id="text-unsere-geschichte"> .. </div>
<h1> in in-main relates to <h2> in ex-main.
<head>
element, it also refuses to put the <header> element into the
<body>. Well, “body-only” is definitely shorter than “no head and
header and som other effects” and the export dispatcher is used for
other exports, too. So, this seems to be the ambiguity we have to deal
with for html export. Probably I didn't find the export
switch for the <header> element, yet. For a “head-and-body” export
the <header> element in the <body> would look like
<header> <h1 class="title">Schreinerei Meier</h1> </header>
That's where the <h1> is lost. On the other hand the <header> part
of the intended example homepage is already sourced out to the
template:
<header> <a id="backlink" href="index.html"><img src="img/logo.svg" alt="logo"></a> <p>Schreinerei Meier</p> <p>ihre Werkstatt für gutes Wohnen!</p> </header>
It doesn't use a heading element, and the style file
📂 formate.css employs some very recent css
magic to address the first and the last paragraph: p:first-of-type
and p:last-of-type. This insight plus the field trip above about
“sectionizing” the <aside> element might deliver ideas for
structural org files aimed at web site architecture. See
also the doc-string of C-h o
org-html-toplevel-hlevel.
Now I can think of three procedures to connect the main content to the template
For this to decide I'll introduce the org mode css procedure borrowed from Fabrice Niessen in the next section.
This section is about tangling designated parts of an org
file into a style file. The short version in Org CSS Construction at
pjs64.wordpress.com skips the details about Niessen's idea and the
implications I derived from it.
Apart from the headlines the only descriptive text, Niessen puts in
his css/js construction file
📂 readtheorg.org is
“Get the lowdown on the key pieces of ReadTheOrg's infrastructure, including our approach to better html export. The setup file links to the web pages.”
This is a rather unobtrusive way of advertising a groundbreaking
method of css organization. With
📂 readtheorg.org Niessen covers the construction of two
css and one javascript file.
imho the javascript parts can be covered by
css3
readtheorg.org doesn't explain much either,
unless the fact that it is possible to export it. The potential that
I see in this css – and javascript and
template and Web site – constructing org file is not
discussed in the repository. Probably I missed something. In my
opinion the multipurpose constructor file delivers for Web sites what
reproducible research is supposed to do for science.
The approach combined with org source code blocks is aimed at replacing the sass and less precompilers for css combined with JavaScript magic. Or a diy alternative or supplement to the JamStack approach, recommended by netlify.
In the exercise example of this blog the css construction
is focused on org's tangling concept, only. Only? The
implementation of the tangling concept also offers diversified
commenting switches, which invite the user to a wide range of
applications; see the :comment and the :padline header arguments
in the Manual's Section Extracting Source Code. The same section
holds other goodies like :link, :mkdirp, :shebang, or
:tangle-mode.
My utilization of org tangling begins with cutting the
example's css file 📂 formate.css into
pieces, putting the pieces into css source code blocks
and embedding them in an outline structure of an org
file. The source code block has to employ a tangling mark, i.e., a
header argument, like :tangle yes or :tangle filename. There are
four levels of customizing the tangling target or any header entry
:tangle path/2/style.css in the header of the source code
block; see the Extracting Source code Section in the
org Manual.:header-args:css:
:tangle path/2/style.css; see the Using Header Arguments Section.#+PROPERTY: header-args:css :tangle path/2/style.css anywhere
into the document, probably in the file headerorg-global-properties; see the Property Syntax
Section.
For the short carpenter's site example it's not necessary to use
either of them, because for :tangle yes every css
source block is filled into a file with the base name of the
org file which contains the code blocks.
Nonetheless I'll include an :tangle ~/www/shtm0/css/shtm0.css in the
property drawers of the sections which contain css code
for the shtm0 example. In the example these are all code blocks, but
the next step for producing different files is close at hand. I don't
know if this is a good idea; the next projects will show.
The header argument :output-dir doesn't work for
tangling, but for source code block output, which is addressed by the
result type :file; see Section Results of Evaluation which also
introduces :file-desc, :file-mode, :file-ext, or the result
format html with :wrap fine tuning. The Section Environment of
a Code Block offers a paragraph about :dir and :mkdirp
corresponding to the working directory. The examples in these
condensed manual sections might also serve a source of inspiration for
publication-related aspects of org source code
blocks. Anyway I'll have to make sure that the 📂 css/
folder exists; see Section 11.3.1 for the corresponding
routines applied in the Test, one, two, three case. |
The adaption of the css to the html export
and the design measures are described in the short version's Section
Org CSS Construction at pjs64.wordpress.com.
For the htmlize11 driven feature of
inline css, especially its failure in batch mode, see the
doc-string of org-html-htmlize-output-type. In contrast with other
applications of htmlize this reflects the situation for
html export of a buffer.12 A controlled construction of htmlize is
facilitated by org-html-htmlize-generate-css.
Get more diy org → html hints in the
doc-strings of |
In the carpenter's Web site assimilation [20] Section Glue HTML and Extract Images delivers the central content of the post. In the extended version the procedure is sketched in Section 11; it gets a structural introduction, a preparation for information retrieval and the glue and image part are split up.
[20]'s glue and image section concludes with the
collection of media into the publication folder. I maintain an image
root folder and determined its sub-directory 📂 shtm0/
for keeping all the files which are from the zip
repository of the example and the files I choose to add myself. In the
org source for the Web pages links to the images were
inserted with file:./img/xxx.yyy where 📂 ./img/ is a
symlink to my image root. In the html export this
📂 img/ directory is a real folder which is supposed to
contain real media.
My image concept usually needs a sub-folder in the
📂 img/ directory of the upload folder. For this to work
the file.copy() of the last line would need a directory check; see
Section 11.4.2 for the routine. In the short version
[20] I don't use this subfolder structure; I just put
all the media into 📂 img/. |
For the extended 1-2-3 version, see Section 11, I
might have been able to combine publishing properties like
:base-extension, :exclude, and :include to utilize the
publishing function org-publish-attachment. For instance I could
have used the method for selecting updated pages to construct a file
list for the :include property and use my image root sub-folder as
:base-directory; see Selecting Files and its preceding section in
the org Manual. It might be far off in this case but a
reasonable solution for other approaches. See Ogbe's solutions,
annotated in Section 13.1 and summarized in Table
5.
The result of the short version [20] was a Web site which is shown as a screenshot excerpt in Figure 3.
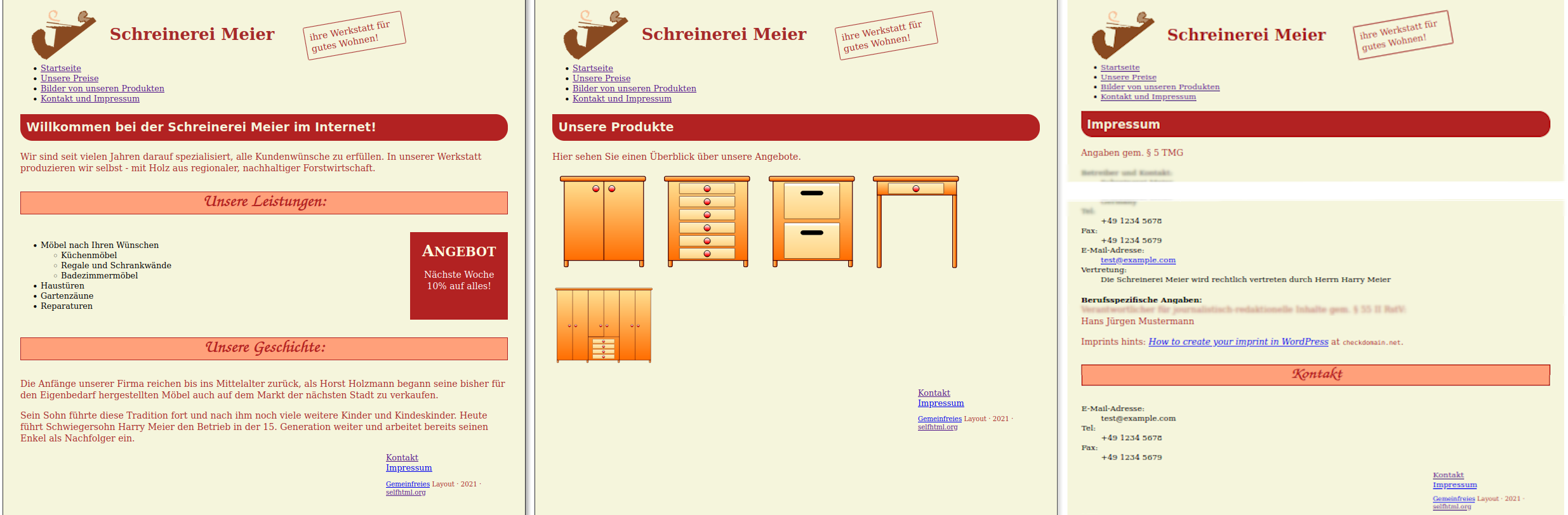
index.html, 📂 products.html, and a shrinked version of 📂 contact.html.Netlify has a very fine grained billing model. I didn't offer the url for the resulting netlify.app as a show case, because – without further investigations – I can't relate the billing for traffic to the bandwidth concept. For me this is another rookie issue like my elisp illiteracy.
Netlify offers some insight into their models but the documentation has the same issues as many other usage manuals. It's about standards not the many implications of a multitude of applications. There's a dedicated Billing Section, and there are many topic related billing parts of every metered feature, like monitoring, visitor access, forms, functions, and large media. But for me even the terminology is so far from my imagination that I had to visit other resources to tackle the issues. The Billing Section links to the second item below, and I don't remember what led me to the first one.
blog.bytefaction.com. According to the url it's about
outsourcing bandwidth to cloudflare. But this might be a
matter of jumping out of a frying pan into the fire.answers.netlify.com.I tend to a more elaborate model which avoids the metered large media feature. For pixelized photos I'd prefer a thumbnail which points to some sources at wikipedia commons or pixelfed; the git hash of a thumbnail at least offers the necessary updating feedback. For info graphics and plots I'd suggest an svg version, or even better the graph producing script with raw data access. That's more like reproducible research. For videos it's even more interesting to reduce the traffic or bandwidth. Videos that are the result of screen casting might be turned into a latex beamer presentation, or a slideshow. Audio for screen casts is usually not based on a script; in the worst case an unedited conglomeration of hmmmms and ehems. Same counts for presentations. So there are many stages in the production cycle to reduce the potential of data volume increments.
The fact that :body-only is not only a <body> issue makes too much
publishing features unavailable. On the long term I think I will go
with the bare model and immensely use R aided xml editing
based on explicit node treatment. Particularly the section Glue HTML
about embedding the body-only exports into the template will probably
move from gluing to node replacement.
But first I want to apply the the short version approach to my initial steps of a clueless preparation of a few org mode stubs – see Section 2. This application is going to include
#+include:. The problem is reported and solved in Section
11.2.3.
The result will be a volatile publication. This time I'm going to
provide the netlify.app url in order to monitor all the
un-billed statistics I can get hold of. And when something unusual
happens I intend to pull the plug. That's the volatile part.
The whole procedure depends on unshared
|
The whole construction is a work in progress driven by the motivation to switch from latex sweave to org mode procedures. There are so many variables, methods and files involved in this process that I'm just happy to derive the necessary steps manually. A proof of concept. While I don't provide the source files at least I've illustrated the scaffold of my image, latex and org file roots in Figure 4.
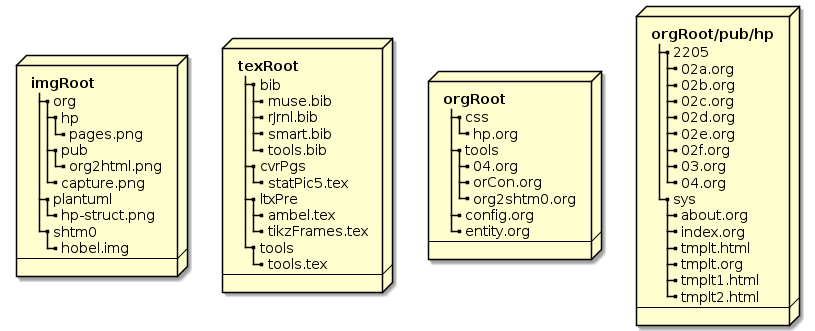
My choice for this next level publishing is about wiring the hard disk
to a publication folder by harnessing symlinks, org
#+include:'s, and org search options. The
org files themselves could provide additional selection
features like tags; see Section 12.3. The symlink
org files in the :base-directory will result in real
html files at the publishing folder. A symlink
📂 index.html in the publishing root will point to the
starting page file 📂 index.html in the
📂 sys/ folder. Here's the :base-directory with its
files, the settings within them, and the features they provide; see
Figure 4 for the file structure.
sys/, the folder with Web site structure files
index.org #+Options: num:t switch on headline
numbers. The text has org file links which turn into
html file links.about.org has two subsections, an internal Web
site link, and an inset picture.tmplt.org is supposed to produce template2205/, a monthly folder
02a.org contains an #+include: of
rel/path/2/orCon.org::#cap-ref-arch with a :lines "1-47"
option; it uses the headline of the referenced section in
📂 orCon.org and add the specified number of
lines. The line specification cuts off the following subsection
structure; this post qualifies for testing the :minlevel
argument. The file also contains table of links to the
sub-02-posts b–f. Note that the sub-02-posts d–f are accessible
through this table only, not by the menu.02b.org and 📂 02c.org
#+include: other sections with an :only-contents t
option. 📂 02b.org substitutes the missing headline
with a horizontal-line concept, while
📂 02c.org uses a headline and an abstract
construction with additional information.02d.org to 02f and 📂 03.org
contatin a plain #+include: with no options04.org is not included in the repository folder
because it's symlink to 📂 orgRoot/tools/04.org
img/ a symlink to my 📂 imgRoot/
css/ a symlink to a css folder in my 📂 orgRoot/
See the org Manual's Include Section for arguments like
:only-contents, :minlevel, or :lines. The settings and features are a result of the procedures in the next Sections 11.2, 11.3, and 11.4. The publishing alist is
(setq org-publish-project-alist '(("hpSys" :base-directory "myOrgRoot/pub/hp/sys" :publishing-directory "~/www/hp/sys" :exclude "tmplt.org" ) ("hpBlg" :base-directory "myOrgRoot/pub/hp/2205" :publishing-directory "~/www/hp/2205" ) ("hp" :components ("hpSys" "hpBlg")) ))
with hpSys and hpBlg sharing the properties below. I removed the
shared properties from the alist above to reduce the code block size
and to empasize the common settings.
:with-toc nil :section-numbers nil :publishing-function org-html-publish-to-html :body-only t :html-doctype "html5" :html-container "section"
The main difference between the two publishing components hpSys and
hpBlg is their timestamp behavior. In the real sys files the
publishing process can track the content, while the #+include: part
of the files in the blg directory prevents from updating checks. All files but the symlink 📂 04.org can be published by org-publish-file.
When I review the file structure I immediately got other ideas for a
proper structure. For example in 2022-06 I'll run into the problem of
having to define a new component. But right now the task is to define
a structure at all, not the structure for every purpose. The most
obvious choice would be 📂 blg/ instead of
📂 2205/. Or starting from the root recursively,
excluding the 📂 sys/ folder. Another idea is to put the
css file into the 📂 sys/ folder.
With an increasing number of files it's probably a good idea to put up
a check list like Table 3. An org table can be
used to control and document the blog entries. The short column names
in Table 3 are designed for direct usage as variables. I
could put this table in my 📂 hp.org file which started
with the css constructor; now the file kind of naturally
grows into the architecture file I was hoping for. First I added the
elisp code for publishing, then the R code for collecting
the image files. But the file still sits in the 📂 css/
folder; it probably will move into the 📂 sys/
department which itself might grow into another structure with a
corresponding table illustration.
| p | f | t | i | s | o |
|---|---|---|---|---|---|
| 2205 | 02a | ORG Capture | i | orCon.org::#cap-ref-arch | ✓ |
| 2205 | 02b | Attachments | i | orCon.org::#attachments | ✓ |
| 2205 | 02c | Capture | i | orCon.org::#capture-2 | ✓ |
| 2205 | 02d | Protocols | i | orCon.org::#protocols | |
| 2205 | 02e | Refile | i | orCon.org::#refile | |
| 2205 | 02f | RSS Feeds | i | orCon.org::#rss-feeds | |
| 2205 | 03 | ORG Help | i | orCon.org::#sec-org-help | |
| 2205 | 04 | ORG 2 Web Site | s | 04.org |
In my first attempt I was working on the original
📂 org2shtm0.org file in my 📂 orgRoot/
then, according to Section 11.2.3 switched to
the #+include: file 📂 04.org representing the
id of the publishing process. Apart from that detour the
whole procedure depends on unshared org macros, custom
org entities, latex macros; see the What's
More Section 12.2.1 for their purpose and Figure 4 for
the involved file structure.
In the pdf construction cycle I have to make sure that
any #+BIBLIOGRAPHY: line is commented. This line is necessary for
the html bibliography procedure handled by the inclusion
of 📂 ox-bibtex.el; see Section 11.2.2.
I first export the latex body from the posting file
📂 org2shtm0.org which delivers
📂 org2shtm0.tex. Then I insert an inclusion macro
\PartIn[2]{} into my latex template
📂 tools.tex.
%-------------------------------------------------- % Org 2 shtm0, publication \PartIn{Org to Website}{rel/path/2/org2shtm0}
📂 tools.tex contains the latex
configuration and all my victims for latex compilation in
a structured ascii manner.13 They are all
commented unless they should be compiled.
The \PartIn[2]{} command shares its purpose of file inclusion with
other constructs like \LineFile[2]{..}, \FileIn[2]{..},
\FileInNN[2]{..}, \starsub[1]{..}, \FileLine[2]{..}, or plain
\input{}. I'll hide the ingenuity of these macros from the curious
reader. The top level scientific definition of \PartIn[2]{} is
\newcommand\PartIn[2]{\newpage\part{#1} \input{#2}}
I'll use two results of this procedure (1) the pdf is ready for upload (2) the aux is the source for html creation.
With the help of Filliâtre and Marché's bibtex2html tools
I manually extract the bibtex entries to
📂 org2shtm0.bib, clean up the entry fields, and copy
both the pdf and the bib file to the
📂 org2shtm0.org folder. bibtex2html is
also used by 📂 ox-bibtex.el; it offers the auxiliary
programs aux2bib for extracting bibliography entries and bib2bib
for manipulating the extract. The main program bibtex2html
htmlizes the bibtex source file and the
<table> snippet.
cd my/docs/tex
cp ltxTmplt.pdf rel/path/2/org2shtm0.pdf
aux2bib ltxTmplt.aux > org2shtm0.bib
bib2bib --remove owner --remove timestamp --remove abstract --remove journal-url --remove language --remove keywords --no-comment -ob org2shtm0.bib org2shtm0.bib
cp org2shtm0.bib rel/path/2
Removing the abstract field might be a bad idea when you plan to use
bibtex2html's feature of printing commented
bibliographies: “If a bibtex entry contains a field
abstract then its contents are quoted right after the bibliography
entry in a smaller font, like this.”
I may consider removing the comments in the bib file
manually. Furthermore I may like to change the sorting of the
bib file. That's a matter of bib2bib configuration; the
flags -s 'author' -s '$date' for example sort by author, then by
date.
Hint form the bib2bib man page: “When sorting, the
resulting bibliography will always contain the comments first, then
the preambles, then the abbreviations, and finally the regular
entries. Be warned that such a sort may put cross-references before
entries that refer to them, so be cautious.” |
Now I test the export inside the :base-directory the first time;
the first time reflects the situation with a symlink
📂 04.org in the 📂 pub/hp/ to
📂 org2shtm0.org in the 📂 tools/ folder
of my orgRoot; see Figure 4. I uncomment, activate or
insert
#+BIBLIOGRAPHY: org2shtm0 plain option:-a limit:t
in 📂 org2shtm0.org and export the file to
html. With installed ox-bibtex.el the
existence of #+BIBLIOGRAPHY: results in two files
📂 org2shtm0.html and
📂 org2shtm0_bib.html. The first is the resulting
html export with a bibliography table snippet called
citation list and adapted citation links. The _bib.html is a
htmlized version of the collected bibliography entries.
The citation link table is inserted at the #+BIBLIOGRAPHY: location.
I could have skipped copying
📂 org2shtm0.bib to the :base-directory and instead
used my/docs/tex/org2shtm0 as bib file path in the
#+BIBLIOGRAPHY: directive. Same results. |
Bug? Citations like \cite{fu2018bom,fu2018bor}
are put correctly in the text and in the citation table, i.e. the
bibliography appendix, but the entry in the bib file
isn't transferred into the html version of the
bib file. For correct transfer they have to separated
into \cite{fu2018bom} and \cite{fu2018bor} by more than a space; a
comma works. Not tested: or added with seperate \nocite{} commands?
I didn't look for the cause of this bug. bibtex2html or
📂 ox-bibtex.el? |
Remember that my intended approach was a 📂 04.org
symlink in the :base-directory linked to my working file
📂 org2shtm0.html. And manually commenting the
#+BIBLIOGRAPHY: directive. In the previous section I called this
configuration the first time.
So what happens when I publish the file from the symlink
📂 04.org? It results in two files
📂 org2shtm0.html and
📂 org2shtm0_bib.html in the :base-directory and
another 📂 org2shtm0.html in the
:publishing-directory. But the base 📂 org2shtm0.html
is the citation list <table> for the reference inclusion. Seems
part of the ox-bibtex.el feature to overwrite this
snippet with the html export of
📂 org2shtm0.org. And the publishing process somehow
enters into the bibtex process before overwriting or a
final clean up.
So, I publish the symlink 📂 04.org and get (two)
📂 org2shtm0.html files. Nice. But I want to keep the
04 signature. My first ideas for possible responses
I began testing items 1–3 and then disovered item 4. When I was ready for publishing the first issue of my volatile Web site I debugged the error commented in the hint below which led to item number 5.
04.org symlink in the
:base-directory to a file 📂 04.org in the same
folder as 📂 org2shtm0.org, i.e.,
📂 orgRoot/tools. This real 📂 04.org
#+include:'s 📂 org2shtm0.org and I can add
publishing features, beginning with the #+BIBLIOGRAPHY: line.org2shtm0.org with the #+BIBLIOGRAPHY:
line another way to put the internal references right is to include
a bib file named 📂 04.bib. This produces the
citations in 📂 04.html and the bibliography excerpt
📂 04_bib.html and includes
📂 04.html in the html export
📂 org2shtm0.html
Awesome. I found a way to overcome the manual commenting and
uncommenting of the #+BIBLIOGRAPHY: line and made room for other
editorial tasks. After publishing the symlink I find
📂 04.html in the :publishing-directory, but
📂 04_bib.html is still in the 📂 orgRoot/
folder, so I finish with
cd ~/orgRoot/Tools
cp 04_bib.html ~/www/hp/2205/
Hint: Don't hide the #+BIBLIOGRAPHY: line in a commented
section. I just made this error by appending a commented appendix
section as the last entry. Then my inclusion file, the real
📂 04.org in the 📂 orgRoot/
folder, cut off all the content after the
#+include: setting. |
In contrast to Glue HTML and Extract Images at pjs64.wordpress.com
I now seperate the html embodiment from the image
treatment. The section Paths and Files is for both the template
inclusion and the image comparison. It probably will be placed more
properly at the beginning of the whole architechture file
📂 hp.org.
Two differences to Paths and Files at pjs64.wordpress.com.
sys/.css/ folder.
The second item ensures an existing folder for the css
tangling further down in an integrated org mode file
📂 hp.org. The header arguments :header-args: :tangle
~/www/hp/css/hp.css in 📂 hp.org expect a
📂 css/folder in 📂 ~/www/hp/.
pub <- "~/myOrgRoot/pub/hp"; www <- "~/www/hp"; setwd (www); pic <- file.path(www, "img"); if(!dir.exists(pic)) dir.create(pic); sty <- file.path(www, "css"); if(!dir.exists(sty)) dir.create(sty); t <- c(file.path(pub,"sys","tmplt1.html"), file.path(pub,"sys","tmplt2.html"));
For development mode I use 📂 css/ and
📂 img/ symlinks; for production mode I have to make
sure to turn them into real folders. The symlink checker
Sys.readlink() is for the
📂 index.html symlink in the root only; it avoids
surrounding the 📂 index.html file in
📂 sys/ twice with the template brace. According to the
help file this is a posix feature not available at
windows.
Looking for "<!doctype" should be expanded to find "<!DOCTYPE"
too. Might be a matter of putting the scan()
function into a tolower() function. The other functions are
list.files(), append(),
length(), and the for(){} control.
listHtml <- list.files(path=www, recursive=TRUE, pattern="[.][hH][tT][mM][lL]?$"); del <- NULL; # sort out for (i in 1:length(listHtml)) {quest=FALSE; # have to include "<!DOCTYPE" also if(scan(listHtml[i],character(),1,quiet=TRUE)=="<!doctype") { quest=TRUE } # doctype test if(Sys.readlink(listHtml[i])!="") { quest=TRUE } # symlink test del <- append(del,quest)} listHtml <- listHtml[!del]
In the carpenter's version Page Assembly and Media Check included
the collection of image src attributes. Now the page assembly is
reduced to file.append(), file.copy() and
tempfile().
for (i in 1:length(listHtml)) { x <- tempfile(fileext=".html"); file.append(x,c(t[1],listHtml[i],t[2])); file.copy(x,listHtml[i],overwrite=TRUE) }
Relative links in #+include:'d org files are prepended
by the relative inclusion path. If I include a file with
#+Include: "../../../tools/orCon.org::#attachments"
| then a relative path like | 📂 ../img/org/capture.png
|
| is translated to | 📂 ../../../img/org/capture.png
|
| A relative path like | 📂 ./img/org/capture.png
|
| would result in | 📂 ../../../tools/img/org/capture.png
|
In any of these cases I need to make sure that the image path begins with 📂 ../img. This is a problem for file 📂 02c.html only, but I'm curiaous about a proper procedure for exchange.
Changing the relative image links exercises xpath and xml node treatment in the external pointer concept of the R package XML. The two pages of Section 3.9 Three Representations of the DOM Tree in R in [15]'s Chapter 3 Parsing XML Content explain the concept. And they raise the awareness for the cloning feature. The description of xmlClone() in the function summary of [15]'s Chapter 6 Generating XML reveals a condensed version, which reflects the pointer-reference distinction in C-functions:
“Create a copy of the xml node or document provided. The element will be cloned to create a new C-level structure. The
recursiveargument indicates whether all the child nodes will be cloned as well, or only the top-level node. Cloning is not the same as assignment. When we clone, we make an explicit copy of the C data structure and return that copy (which may then be assigned to an R variable). Simply assigning an internal node to a variable does not make a copy of it, unlike most objects in R, but merely copies theexternalptrobject. As a result, a simple assignment means any subsequent changes to the node will appear in all references to it. In contrast, when we clone a node or document, the original and the copy are independent copies and changes to one are not reflected in the other.”
— Description of xmlClone() in Section 6.8 Summary of Functions to Create and Modify XML of [15]'s Chapter 6 Generating XML, p.224
After all this is just a motivation for harnessing node related
treatment in xml or html files. Perhaps for
using R, too. The image detour begins with excluding html
symlinks by append()'ing
Sys.readlink() positives from the html
file list acquired by list.files() in a
length() for(){} loop.
listHtml <- list.files(path=www, recursive=TRUE, pattern="[.][hH][tT][mM][lL]?$"); # sort out symbolic links del <- NULL; for (i in 1:length(listHtml)) { del <- append(del,Sys.readlink(listHtml[i])!="") } listHtml <- listHtml[!del]
In the reduced file list
htmlParse() prepares for node extraction of src
attributes by getNodeSet(). The xpath
checks for <img> elements with src attributes which do not begin
with ../img/ or http.sub() replaces the first occurrence of its search pattern with the
relative path to the parallel 📂 img/ folder. The
assignment operator sets the value for the src attribute.for (i in 1:length(listHtml)) { duc <- XML::htmlParse(listHtml[i]); # str(duc) imgNode <- XML::getNodeSet(duc, "//img[ not ( starts-with(@src, '../img/') ) or not ( starts-with(@src, 'http') ) ]"); li <- length(imgNode); if(li>0) { for (j in 1:li) { XML::xmlAttrs(imgNode[[j]])["src"] <- sub("[A-Z/ a-z.-]+/img/","../img/", XML::xmlAttrs(imgNode[[j]])["src"]) } dummy <- XML::saveXML(duc,listHtml[i]) } }
Same selection process as in the previous section for the html files with the objective to skip symbolic links.
listHtml <- list.files(path=www, recursive=TRUE, pattern="[.][hH][tT][mM][lL]?$"); del <- NULL; for (i in 1:length(listHtml)) { del <- append(del,Sys.readlink(listHtml[i])!="") } listHtml <- listHtml[!del]
Read the src and data attributes in <img> and <object>
elements, respectively, by applying
getHTMLExternalFiles() and
append()'ing them to the img collection. The
attribute xpQuery of getHTMLExternalFiles() is an
xpath expression and defaults to c("//img/@src",
"//link/@href", "//a/@href", "//script/@href", "//embed/@src").
img <- NULL; for (i in 1:length(listHtml)) { duc <- XML::htmlParse(listHtml[i]); # str(duc) xpq <- c("//img/@src", "//object/@data"); img <- append(img,XML::getHTMLExternalFiles(doc=duc, xpQuery=xpq)); }
Note that the image paths derived from the orgRoot variable pub contain a symlink
unique() the image paths and remove the http paths with a grep() selector
uImg <- unique(img); pImg <- uImg[grep("^http",uImg,invert=TRUE)]
sub() selector and file.path()
file.exists() and
md5sum() – assuming that (1) all file paths
begin with "../img/" and (2) the Web site only has one level of
folders – and overwrite them with file.copy() if necessarydirname(), dir.create(), dir.exists(), and file.copy().for (j in 1:length(pImg)) { cImg <- sub("^[.][.]/","",pImg[j]); fPic <- file.path(www, cImg); fPub <- file.path(pub, cImg); if (file.exists(fPic)) { sPic <- tools::md5sum(fPic); sPub <- tools::md5sum(fPub); if(sPic!=sPub) { file.copy(fPub, fPic, overwrite=TRUE) } } else {dPic <- dirname(fPic); if(!dir.exists(dPic)) { dir.create(dPic,recursive=TRUE,mode="0755"); } file.copy(fPub, fPic); } }
My method doesn't include svg files; they would be
found by looking for the data attribute in an <object> element.
objDat <- XML::getNodeSet(duc,"//object/@data"); # str(objDat)
That's because I didn't find a proper way to address backend specific image production. I'd prefer pdf for latex and svg for html, but as long I can't figure it out, I'll stay with png for both.
I'm still working on inclusion of my favourite latex tikz candidate for infographics, for situations where R's graphics solutions graphics, lattice or ggplot2 are too tedious to design. But this approach went into competition with asymptote and gnuplot. Or plantuml and pure graphviz solutions. Except for latex tikz I've set up org babel blocks for these graphics tools to put them up for experimental trials.
The backend specificity also applies to tables, but the org solution in this case is much more advanced. It even expands to an amazing ascii mode spreadsheet feature, which might be the sole reason to turn into an org mode monk.
The change log of org mode offers a new procedure of backend independent one for all solution, i.e., svg.
“org babel now uses a two-stage process for converting latex source blocks to svg image files (when the extension of the output file is
.svg). The first stage in the process converts the latex block into a pdf file, which is then converted into an svg file in the second stage. The tex → pdf part uses the existing infrastructure fororg-babel-latex-tex-to-pdf. The pdf → svg part uses a command specified in a new customization,org-babel-latex-pdf-svg-process. By default, this uses inkscape for conversion, but since it is fully customizable, any other command can be used in its place. For instance, dvisvgm might be used here. This two-part processing replaces the previous use of htlatex to process latex directly to svg (htlatex is still used for html conversion).Conversion to svg exposes a number of additional customizations that give the user full control over the contents of the latex source block.
org-babel-latex-preamble,org-babel-latex-begin-envandorg-babel-latex-end-envare new customization options added to allow the user to specify the preamble and code that preceedes and proceeds the contents of the source block.”
— New options and new behavior for babel LaTeX SVG image files change log entry for version 9.5, accessed 2022-07-26.
For me one of the most intriguing aspects of Internet pages is their cloaking mechanism for links. They hide all their ingenuity behind clickable words. And the most the reader can expect from the design of a complete Web site is a cloud of tags, maybe even categorized, but in the worst case automatically generated. On the other hand the digital high performance machines could produce a table of contents, prematter, backmatter, footnotes, captions, indices, and biblographies which are the main source of quickly getting an informed impression of the content and to acknowledge the external contribution of larger documents. For reintroducing these features in a cms we would have to browse through a jungle of extensions and fill a multitude of database tables.
Another unpleasing feature of the blogging mainstream is the reduction to linear storylines. New css features and increasing integration of svg are on their way but even with the old css the user drowns in a sea of configurations. For the creation of something in the range of o'Reilly's Head First series the author is urged to employ a whole industry of publication professionals. In this regard org mode and its emacs base can offer their embracing features, as Niesson's example shows.
For me it's important to use a tool which offers a starting point for perfect latex and html and texinfo exports, instead of reduced approaches like rstudio-markdown-html-rshiny or latex-sweave-pdf. Of course, the configuration efforts will increase, because I'm dealing with different media or formats; with different concepts. imho that should be the real realm of responsive design discussions; or barrier-free access, to use a term that deals with people instead of devices. I can't produce a proper pdf from a html markdown, nor can I produce an animated html page from dvi latex. While it might be a proper idea to produce a page oriented beamer presentation from latex; or to transform a tikz portable graphics format14 to svg.
With regard to the simple example I'll sketch some expansions into a “what's next” agenda.
Apart from the :publication function which already can be a list
of functions I identified three injection methods for publishing
hooks.15
The main publishing hooks are called :preparation-function and
:completion-function; The corresponding Manual entry tells us that
“functions listed in these properties are to be called before starting
[or after finishing] the publishing process, for example, to run
make for updating files to be published [or change permissions of
the resulting files]. Each function is called with a single argument:
the project properties list.” I've no idea what the single argument
project properties list means. For getting ideas I sketched Ogbe's
[16] usage of pre- and postprocessors in Section
13.1.7.
The function list org-publish-after-publishing-hook is another spot
for getting information; it's called in org-publish-file which is
part of org-publish-projects and org-publish-current-file. The
default arguments are the source and the target file paths.
For me the syntax for an elisp shell call on
emacs level might be the entry to elisp
programming. Such a shell call looks like (shell-command "ls"). In
Table 4 I sorted the set of related definitions and
commands into short and longer commands and removed their common
prefix shell-command-.
completion |
saved-pos |
-save-pos-or-erase |
dont-erase-buffer |
history |
sentinel |
-set-point-after-cmd |
separator-regexp |
on-region |
switch |
completion-function |
with-editor-mode |
regexp |
to-string |
default-error-buffer |
For asynchronous calls – which don't block the whole
emacs instance – there are commands like start-process
or start-process-shell-command; see Xah Lee's Elisp: Call Shell
Command [10] at xahlee.info or the whole
📂 subr.el with the basic elisp
subroutines.
Ogbe's [16] usage of a shell command regards CSSTidy, sketched in Section 13.1.
Two of my next steps begin as a matter of the individual post. The first one is already realized on this volatile example site
href of the
anchors <a>. Sort and unique them.The full line of “self reference” approaches begins with the table of contents, the list of figures or tables, and indexes; next we can add appendices with all kind of specific supplemental information, usually arranged in a back matter part, or the content related information of the pre-matter. What about mini tocs, footnotes, endnotes, examples, theorems, definitions, exhaustive info boxes or other boxes for warnings, hints, notes? The LaTeX Companion [12] dedicates the first Chapter The Structure of a LaTeX Document to most of these meta informations. The Subsection 3.3.3 amsthm – Providing headed lists, Section 3.3 List structures in [12]'s Chapter 3 Basic Formatting Tools provides for more. And o'Reilly's Head First series shows the variety in non-math books.
Keeping track of all the references for the whole Web site is a major task of the cms. Administrative tasks yield another field of applications. Both of them constructing their own display modules, just like the mysql php combination of the global players. In the case of bibtex my coordinated org mode approach produced both a table for the posted file and an additional bibliography file; and a pdf which is not derived from the templated html export. I consider this a clean start. And this wouldn't be a What's more section if it didn't offer more about bibtex, links, and “self scraping.”
To get started I only put up the resulting files for the bibliography and the pdflatex compilation; see Section 11.2 for elaboration. To step into “reproducible publication” I will have to provide
config.org, my setup
file, together with the corresponding latex macros and
the elisp code for the macro edits. I didn't configure
the latex compilation in org mode, yet?,
and the listings macros are still in the development
cue, too. There might be other solutions like latex's
minted related to python's
pygments. For the html export
org employs htmlize, which reflects the current buffer
theme.~/.emacs file.
Next step is to compare org-bibtex,16 reftex,17
ox-bibtex,18 the very new19 org-citation, and external libraries like RefManageR
or services like zotero, which probably includes
expanding to linked data. The org-citation approach is
done with contribution of Kitchin's org-ref which
“is an emacs-lisp module to handle bibliographic citations, and references to figures, tables and sections [… and] was written first for use in org-mode, and for reasonable export to latex. It does not work well for any other export (e.g. html) for now.”
— Using org-ref for citations and references a 2014-05-13 blog entry by Kitchin atkitchingroup.cheme.cmu.edu.
org-ref is an approach with Citation Style Language. Kitchin doesn't
work with ox-bibtex or bibtex2html: “I don't
plan to use bibtex2html in org-ref. It is not easy to install on
Windows. The approach org-ref will take is described here.”
github org-ref issue 101, 2016-01-10. The version org-ref
2.0.0, accessed 2021-10-01, available at melpa, requires
dash-2.11.0, htmlize-1.51, helm-1.5.5, helm-bibtex-2.0.0, ivy-0.8.0,
hydra-0.13.2, key-chord-0, s-1.10.0, f-0.18.0, pdf-tools-0.7,
bibtex-completion-0 1.1.1.
For the acknowledgment aspect I'm using hints from Cite it Right [8], Who Did What? The Roles of R Package Authors and How to Refer to Them [9], and Free Software, Free Society [7].
To extract the html anchors to several indices and to insert back reference anchors could be another option. Here, my reference for insertion is [15]'s Chapter 6 Generating XML. And perhaps I would have to restructure the descriptive parts of my org links.
In my first long version I didn't put every citation into a bibliography link. I think the links to R functions or even Manual pages should be part of a different info system. xpath mediated through [15]'s Chapters 3 Parsing XML Content, 4 XPath, XPointer, and XInclude, and Chapter 5 Strategies for Extracting Data from HTML and XML Content sets the stage.
With this preparation I can compare the efforts
For the anchor's href attributes there's another challenge: bookmark
management. Ever run into http 404 of other pages? It
hurts even more frome the own pages. In 2008 I found joomla bookmarks to be a major inspiration for this management;
complemented by linkagogo (still http, no s)
and memotoo to collect firefox bookmarks or
ie favorites. Where memotoo also offers
ideas for address and eMail management, particularly the
syncml background. They might be thought to be outdated
by pocket or reddit, but we all know that
these startup goodies quickly turn into price tagged data collectors;
see the del.icio.us to pinboard transformation.
For ideas about numbered theorems or examples see the pre-defined
macros in the org Manual's Section Macro Replacement.
It contains the concept of custom counters in numbered theorems or
examples or exercises that can be produced by the pre-defined macro
n(m,x).
In the forms n, n(NAME), and n(NAME,ACTION) this macro
implements custom counters by returning the number of times the macro
has been expanded so far while exporting the buffer. You can create
more than one counter using different NAME values. If ACTION is
"-" the
previous value of the counter is held, i.e. the specified counter is
not incremented. If the value is a number, the specified counter is
set to that value. If it is any other non-empty string, the specified
counter is reset to 1. You may leave NAME empty to reset the
default counter.
For the construction of theorem environments in org I collected four sources
This might be useful on a single page. But for distributed pages there has to be a linking idea like the one concatenating the html version of a large book series by Julius O. Smith III. – presenting, for example, Physical Audio Signal Processing. imho Smith's solution is not maintainable in that form. The discussion above could inspire other approaches.
As we can see from Section 11.4 the html image elements can be handled by xml node recognition. In this section I back up this practice with Temple Lang's statements about regEx not being a solid solution for handling xml. As an exercise I invite the reader to my expedition where I was looking for some background information of the media files in the borrowed exercise layout and reasoned about license aspects. Then I set the scene for another xml node based information retrieval of license information with regard to latex's list of figures mechanism.
Remember, the exercise layout was borrowed from selfhtml.org
(German) and stated as public domain; zip and preview
(gooTrans) provided. It belongs to an html intro called
HTML Einstieg (html Intro → gT). The images needed for
the exercise are from the zip. But first some quotes about
the xml node discussion.
“While we have not formally introduced the R functions for working with xml content, it is useful to note that the rich structure and formal grammar of xml makes it easy to work with xml documents. For example, we can find all
<email>elements, or all<r:func>or<r:package>nodes. We can even locate the<section>node in a book which is, e.g.,
- within a chapter whose title contains the phrase social network and
- which has a paragraph with
<r:code>that contains a call to load the graph package.These are significantly harder to do robustly with markup languages such as latex or markdown since they do not have formal grammars. Typically, people use line-oriented regular expressions for querying such documents and so cannot use the hierarchical context to locate nodes. This also makes it much harder to programmatically update content.”
— Example 2-1 A DocBook Document of Section 2.3 Examples of XML Grammars in [15]'s Chapter 2 An Introduction to XML, p.30
That's a statement in the introductory chapter about xml. But it really gets interesting when this memorandum is translated into action, which is the topic of [15]'s Chapter 6 Generating XML.
“Parsing and querying xml is more difficult using regular expressions than with an xml parser, and it is especially challenging for html due to its often irregular or malformed structure. With an xml parser, we can work with the tree and individual nodes. We can query and modify nodes of interest and adapt the tree. We can then serialize the result back to a string if we want, e.g., to write to a file. In other words, creating xml content via string manipulation works adequately, but we typically want to operate at a higher level with nodes and trees. By parsing the string content, we can continue to think in terms of working with tree and node objects.”
— Section 6.1 Introduction: A Few Ideas on Building XML Documents in [15]'s Chapter 6 Generating XML, p.184
Also as part of this xml editing chapter Temple Lang concedes that direct text manipulation and regEx is sometimes useful. He enciphers this into vectorized generation of XML.
“We have indicated that creating node objects and combining them into trees using
newXMLNode()and the other functions is a good and robust approach to create xml content, and that creating xml by pasting strings together is less robust and flexible. However, there are occasions when string manipulation to create xml/html content is useful. These are typically when we need to create many nodes that have the same structure but with different values in the content or attributes.”?XML::newXMLNode
— Section 6.5 Vectorized Generation of XML Using Text Manipulation in [15]'s Chapter 6 Generating XML, p.206
Unfortunately there's much more to know before applying this advance information. Fortunately the book [15] provides the tools and plenty of examples; see Section 12.2.2 for related chapters. Unfortunately some of the examples are not accessible any more. In the quoted section I also recommended to back up the studies by the usage of another book [14] developed by practitioners of political sociology. They provide a – still available – repository of their examples.
Or you can just follow my example in Section 11.4.1 and
combine it with the challenge sketched in the rest of this section,
which reflects on the exercise layout from selfhtml.org (German)
stated as public domain. The following block is related to the images
in the corresponding zip file.
image-search.org
I'm introduced to the insight that the rocking chair, for example,
needs the attribution
<a href="https://www.vecteezy.com/free-vector/rocking-chair">Rocking Chair Vectors by Vecteezy</a>
The 📂 desk.svg is borrowed from the
wikimedia commons 📂 ryansdesk.svg. For the
unused 📂 x-tree.jpg I followed an image-search.org
link to the bing engine which brings up the file
📂 tree55.jpg at free-clip-art-images.net. For the
📂 hobel.svg icon yandex – mediated by
image-search.org again – found similar sources at cleanpng.com,
dlpng.com, pngwing.com, and ya-webdesign.com, all of which claim
personal usage only. I could assume that the red point version at
selfhtml is a selfhtml product, but I
wouldn't provide the file as public domain. So, I take three measures
hobel.png
As an additional measure I contacted Selfhtml e.V. for a statement about their public domain statement; the chairman Scharwies confirmed this status.
Mr. Scharwies, since 2016 chairman of the ngo Selfhtml e.V. told me that the exercise zip contains pictures, which are collected mainly from wikimedia commons.
I can find most of the images in the category SVG Furniture at
commons.wikimedia.org. Based on the available information I'm
constructing a check list to decide about the inclusion of the files.
commons.wikimedia.org/wiki is
📂 File:Nuvola_filing_cabinet.svg. While the file itself
resides at https://upload.wikimedia.org/wikipedia/commons/b/bf.
For org export both uri's in the plain form
[[URI]] look like an svg, which for the first link
results in
<object type="image/svg+xml" class="org-svg" data="https:// \ commons.wikimedia.org/wiki/File:Nuvola_filing_cabinet.svg"> Sorry, your browser does not support SVG.</object>
(The backslash is a manually inserted linebreak.) For the second link
this is the expected translation. But if I load a page containing the
translation of the first link the browser shortly tries to embed the file as
svg object and then immediately switches to the
...cabinet.svg page at commons.wikimedia.org. If a page contains
multiple links like this the browser arrives at the last of these
wiki commons pages. This doesn't
happen when I include the uri in a named link like
[[URI][name]]; see the org Manual's Section Links in
HTML export.
If I want to state a by-sa copyright for my own work the proposal at
creativecommons.org offers the code
<a rel="license" href="https://creativecommons.org/licenses/by.sa/4.0/"> <img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-sa/4.0/88x31.png"/> </a><br />This work is licensed under a <a rel="license" href="https://creativecommons.org/licenses/by-sa/4.0/">Creative Commons Attribution 4.0 International License</a>.
When quoting another person's work I can do it in situ or at a central
location, the list of figures; see Section 12.2 for more
reference lists. latex's list of figures depends on
floating figure environments or manual \addtocontents{} and
\addcontentsline{} entries. Usually I would think of an org mode macro to translate the license information to
latex's figure list commands and to the html
code above. The list of figure files of latex might then
be combined with with xml node retrieval of
html media elements like <img>, <object>, or
<video>, which in turn can be pointed at the original site to parse
license information.
An example for accepted in situ quotation infos is provided by the wikimedia commons entry How to Give Attribution. It recommends the caption in Figure 5 for the example of a flickr source.

How to attribute authors of the CC works will depend on whether you modify the content, if you create a derivative, if there are multiple sources, etc. But the caption in Figure 5 is supposed to be an ideal attribution note because it includes the:
The example above works for tedious in situ maintenance of a few external contributions. It will show proper results for latex and html export. The LaTeX Companion [12] offers background information in Section 2.3 Table of Contents Structures and expands thoroughly in Chapter 6 Mastering Floats.
My example in Section 11.4.1 shows the node treatment in action and [15]'s Chapter 6 Generating XML provides the tools for constructing an html snippet comparable to the bibtex2html processes in Section 11.2.2. Parsing the target uri's for retrieving the information is an option, if it's worth the effort; there's plenty to discover.
I wonder if the study of [3]'s Chapter 11 Emacs Lisp
Programming would put me into a position to turn the procedure into a
:publishing-function or begin with a hook; see Section 12.1. I'm sure that emacs has some resonable access to
libcurl, too. DuckDuck goes for Syohex's
emacs-curl and Xu Chun Yang's
curl-to-elisp. But coming from the multiple
options of Python's Beautiful Soup or nltk
I'm happy to have arrived at a basic understanding of
http with the help of Temple Lang's
XML. Don't hurry, be happy.
The short version example of this document is a one level Web site. All html files are in the root. And for the example I imputed a template. In the long version postings and structural files get their own folder. But more content will raise the challenge of a further expanded folder structure. There many options because the physical location of the files doesn't have to reflect the information architecture. In this lookout section I'm collecting ideas for the implementation of both folder and information structure. I'd consider Section 11 as the generator for the second tangible product in this regard.
The fsfe Web site building shell scripts can help for identifying the main topics of the issue. The approach of the fsfe team is to use and painstakingly edit xml and xsl files for every purpose. Apart from the discipline this measure takes it's an absolutely transparent process. So, by experimenting with Morville's wireframe and blueprint design [13], Chapter 12 Design and Documentation I can assume to get some flesh on the bones of a structural skeleton.
That only regards the public elements of an information system. For structuring a private or single person's publication's efforts my major field of interest is to extract elements of my work to the publishing stage. I think about
readtheorg.org. The problem to explode the whole
work into single chapters or sections, in order to reduce the
resource usage, might be addressed by manual selection,
xml aftermath, or texinfo procedures.
For choosing sources of publication org publish first
draws on contents of the :base-directory with an optional
:recursive t expansion. The choice depends on the :base-extension
which defaults to org files. See [20]'s Section
Glue HTML and Extract Images for an expression to choose media files. The two
properties :exclude and :include deselect and select on a regEx or
file basis, respectively; see Section Selecting Files of the
Manual's Publishing Chapter.
:publishing-directory if its
counterpart org file in the :base-directory is missing
and (2) inserting the css file link.
:completion-function cm2 links to Rose's
worg entry Publishing Tree menus for Org-files
[21]. The function is derived from
org-publish-org-sitemap and reads a menu structure from a
dedicated syntax and somehow combines it with the
auto-sitemap. According to cm2 the function “shows how to get
property values for the org-publish-project-alist.”Opposed to that statement for me the main information in this linked blog is to manually provide an intuitive syntax for the necessary infos of a menu structure:
#+STYLE: entry:preparation-function to call a shell script. For
example, by invoking the stream editor sed with
something like href="@MYLOC@/stylesheet.css" />.
The publishing scaffold below contains the idea of putting a symbolic
link of a file into the publishing folder. In the corresponding link
source the sections marked by SELECT_TAGS like the default
:export:, or everything but EXCLUDE_TAGS, default :noexport:,
are extracted for publishing; see the Export Settings Section in the
Manual's Exporting Chapter and the doc-strings of
org-export-exclude-tags or org-export-select-tags.
The search options in file links combined with #+include:21 are another source of
inspiration. Or the concept of attachments.
For access to the absolute root of the finally deployed Website we can
employ the org buffer entry #+HTML_LINK_HOME:, corresponding to
org-html-link-home. And consult the doc-strings of
org-html-link-use-abs-url, org-html-home/up-format,
org-html-link-up.
In an html export something like
[[file:./r.org::#graph-mod][R Graphic Models]] is turned into the
html anchor
<a href="./r.html#graph-mod">R Graphic Models</a>
An ID search option like [[file:./rG.org::#ch1]] would include the
corresponding ID as href="./rG.html#ch1"; see Links in HTML export
and Publishing links. These references assume very disciplined
organizational measures, which are very hard to maintain in something
like blog entries. So I suppose the linking mechanism is designed for
📂 index.html files which reflect the Web site
structure.
Here's a typical ill-structured tree of ideas about wiring the hard
disk to a publication folder by harnessing symlinks, org
#+include:'s, and org search options. The
org files themselves can provide additional selection
features like tags.
blog/
index.org2020-04-25.org symLink → relative/path/2/foo.org
2021-05-29.org symLink → rel/pa/2/bar.org
book/
index.orglnx.org → /abs/path/2/00far.org
rGraphMod.org contains
#+Include: "rel/pa/2/r.org::Graphical Models" :lines 2-
xml.org contains [[file:.lnx.org][WebTech Cmd Line]]
tuts/
index.org
sound.org contains
* sec 1 #+Include: "rel/pa/2/hlmhltz::#fourier" :lines 2- ** sec 1.2 #+Include: "rel/pa/3/physics::#wave" :lines 20-58 * sec 2 #+Include: "rel/pa/4/math::#axiom6" :only-contents
xml.org contains [[file:blog/2020-04-25.org][Insight]] and
[[file:book/lnx.org::#apx2][Data]]
index.orgThe real files in this tree, opposed to the symlinks, would contain the Web site structure. I can think of three already available mechanisms for automatic registration of the symlinks and population of the index files
:sitemap-.. properties triggered by :auto-sitemap t; see Section
Generating a sitemap. The default sitemap procedure generates a
plain list of links to all files in the project, and can be customized
by :sitemap-function.:publishing-function (org-rss-publish-to-rss). Its doc-string
leads to 📂 ox-rss.el. So basically it seems to be
designed as an export feature. Well, org publish itself
is also integrated in the ox- elisp family. For the
rss feature see Blogging from GNU Emacs a 2013-09-25
blog entry by Bastien Guerry at bzg.fr.Diving into theoretical aspects of information architecture can be a distracting mental training effort; see Section 11 for practice. I'll just add one thought about long documents: if I happen to produce very long blogs I'd have to think about splitting the pages. There are css solutions for pagination, but I prefer structural splitting. The explosion to small chapters or sections might be solved by texinfo html exports. I'm talking about texinfo features, not org mode exports; they might already be integrated into org mode or emacs like htlatex for interpreting latex snippets for org mode html export.
The combination of exports and the template is part of the image collection code in [20]'s Section Glue HTML and Extract Images, but there are other options for the expansion of the export files:
:html-preamble
my-blog-header and :html-postamble ,my-blog-footer for inserting
the header and the footerw3.org.For the org mode approach the first idea is the most attractive one. Just like Niessen's css tool it offers a self documenting environment for template development. This procedure is sketched in [20]'s Section Glue HTML Expanded. The template code with the noweb reference is not a valid html document, but this is solved in the short example by a previous tangling procedure. I still can't escape the short R code in Section 11.3.3. Perhaps I have to think it as elisp solution? As a elisp not-even-rookie?
Why worrying about tangling, nowebbing, whatever? I can just cut the
template file into – in this simple case – two pieces, put the export
in between, and save it in my local upload folder. With the
linux cat command this process looks like
cat tmplt1.html index.html tmplt2.html > ~/www/shtm0/index.html
Maybe it's also helpful to know that linux commands can work with the standard input represented by a dash
cat index.html | cat tmplt1.html - tmplt2.html > ~/www/shtm0/index.html
With these commands at hand the fusion of the web pages would be part of a bash script. Which can be included in and triggered from an org file source code block. But my horizon didn't evolve to the bash script loop skills, yet.
For my skills it still is easier to stick to R. But it seems to be kind of a handicap, too. The code for the short version is part of [20]'s Section Glue HTML and Extract Images, the long version is offered in Section 11.3.
A cost-effective solution within netlify could be the
netlify command line interface; see Get started with
Netlify CLI entry at docs.netlify.com. The billing system of
netlify involves build minutes for automatic
deployments via github or gitlab
repositories. As far as I deciphered the netlify cli
process it employs manual deployments from a local git
repository, which doesn't count for billing. This approach should even
work for collaborative configurations.
wordpress offers a xmlrpc interface that works with free accounts, while the rest api is for the paid plans only. The xmlrpc approach is sketched in [15].22 But it consumes much effort for serving serialization, tagging, media upload and the whole cms structure, while resulting just in a blog entry with tags. The free version, for example, doesn't provide mathjax support. Nonetheless the xmlrpc interface invites to examine related blogging giants like google's blogger sphere.
Then there are some media sites like medium.com; unfortunately
the mathjax restriction also counts for medium.com, but
at medium.com they offer a free rest api.
Anyway it's not an option to point out the currently 10 best hosting solutions, because they already changed when such an endeavor is finished.
By working out the details of my next publications steps I began to
see connections to the Amaya project documented at w3.org. The
corresponding mail archive ended in 2010, if I dare to neglect four
outliers until 2014. imho amaya was the most central
project of the World Wide Web and it drowned in the sea of knowledge
it was supposed to discover. I think org →
emacs → gnu linux has the tools for a
revival, but there's no reason to focus on the Internet. The Web is
just another medium. The main objective is information
architecture. And to be reliable it has to be freely accessible,
that's the realm of the Free Software Foundation, which in turn is
deeply ingrained in the same gnu linux environment. The
content of the short version of this blog describes one possible
workflow for the first steps; with the following quotes I invite the
reader to draw connections from the second long version to
amaya.
For shifting the focus away from the Internet the corresponding toolbox won't be an all including software in a browser; it's not helpful to interpret any information-related topic in terms of Web technology. The real challenge is to make the Internet available as the democratic medium it was designed for. The amaya project was aimed at this target, so I find it helpful to sketch the motivation and environment for amaya presented in Weaving the Web [1].
annotea, xtiger and the amaya documentation deliver the specifications for a single Web site. The last chapter of [1], Information Management: A Proposal, delivers the specification for the World Wide Web presented in 1989 and 1990. And here are the book parts mentioning the amaya project. First it's about inria as a connecting link between grif, arena, and amaya:
“cern's resignation left the consortium without a European base, but the solution was at hand. I had already visited the Institut National de Recherche en Informatique et en Automatique (inria), France's National Institute for Research in Computer Science and Control, at its site near Versailles. It had world-recognized expertise in communications: their Grenoble site had developed the hypertext browser/editor spun off as grif that I had been so enamored with. Furthermore, I found that Jean-François Abramatic and Gilles Kahn, two inria directors, understood perfectly well what I needed. inria became cohost of the consortium. Later, in early 1996, we would arrange that Vincent Quint and Irene Vatton, who had continued to develop grif would join the consortium staff. They would further develop the software, renamed amaya, replacing arena as the consortium's flagship browser/editor.”
— Weaving the Web [1], Chapter 8 Consortiuum p.101f
Then some explanations about the tasks of amaya; to me they just sound like bluefish or geany.
“In 1996 we negotiated the right to the grif code from inria and renamed it “Amaya.” It is designed completely around the idea of interactively editing and browsing hypertext, rather than simply processing raw incoming html so it can be displayed on the user's screen. amaya can display a document, show a map of its structure, allow the viewer to edit it, and save it straight back to the Web server it came from. It is a great tool for developing new features, and for showing how features from various text-editing programs can be combined into one superior browser/editor, which will help people work together. I switched from aolpress to amaya.”
— [1]'s Chapter 9 Competition and Consensus, p.119f
Towards the end of the book, it develops to a dense multitasking environment with immense integration needs. Even if it just touches the usual markup languages. And for collaborative work the book mentions jigsaw.
“We are only in the early stages, but we now have an environment in which people who are collaborating with the consortium write and edit hypertext, and save the results back to our server. amaya, the browser/editor, handles html, xml, Cascading Stylesheets, Portable Network Graphics, and a prototype of Scalable Vector Graphics and Math ML. While we have always developed amaya on the linux operating system, the amaya team has adapted it for the windows nt platform common in business, too. I now road test the latest versions of these tools as soon as I can get them, sending back crash reports on a bad day and occasionally a bottle of champagne on a good one.
We are using our open source java-based server, jigsaw, for collaborative work. For example, jigsaw allows direct editing, saves the various edited versions of a document, and keeps track of what has been changed from one version to the next. I can call up a list of all versions, with details about who made which changes when, and revert to an older version if necessary. This provides everyone with a feeling of safety, and they are more inclined to share the editing of a piece of work. jigsaw and amaya allow our team space to come alive as our common room, internal library, and virtual coffee machine around which staff members who are in France, Massachusetts, Japan, or on an airplane can gather.
Making collaboration work is a challenge. It is also fun, because it involves the most grassroots and collegial side of the Web community. All Web code, since my first release in 1991, has been open source software: Anyone can scoop up the source code – the lines of programming – and edit and rebuild them, for free. The members of the original www-talk mailing routinely picked up new versions of the original Web code library “libwww.” This software still exists on the consortium's public server,
www.w3.org, maintained for many years by Henrik Nielsen, the cheerful Dane who managed it at cern and now mit. libwww is used as part of amaya, and the rest of amaya and jigsaw are open source in the same way. There are a lot of people who may not be inclined to join working groups and edit specifications, but are happy to join in making a good bit of software better. Those who are inspired to try amaya or jigsaw, want to help improve them, develop a product based on them, or pick apart the code and create an altogether better client or server can simply go to thew3.orgsite and take it from there, whether or not they are members of the consortium.”
— [1]'s Chapter 12 Mind to Mind, p.170f
The annotea specifications are easily contained within org mode hyperlinks and necessarily separated from the rss export. And I think inventions like bookmarklets or annozilla are outdated by linked data.
I can see many initiatives which are willing to invest the effort for generating informed decisions without outsourcing the reasoning to so called professionals linked to institutions of excellence. I might be on the way to offer proper tools; I'll see if they deliver the intended freedom for my purpose chain thought → word → act.
“Who's got the privilege to know, has the duty to act.”
— According to a 2021-09-08 post atthewisdomofpeople.comJill S. Baron attached this quote, in a slightly different form, to Alberst Einstein in the Preface to Rocky Mountain Futures: An Ecological Perspective (Washington: Island Press, 2002)
No matter if Einstein said it, the duty to act depends on the words which communicate the thoughts into action. The idea of putting thoughts into words before acting on them is one essential step in human relations. It also acts as a buffer. So putting it into an emacs buffer is definitely a good start.
I just offer Supplemental Material for the carpenter's Web site assimilation [20]. The files for the construction of the advanced rookie site are listed in Figure 4 and their purpose is illustrated in the What's More Section 12.2.1. It's because in the current state of transition the files contain too much outdated approaches.
Apart from the linux kernel the System Information of [20] is also the same in the long version. The carpenter supplements are still available at https://bitbucket.org/StPjotr/shtm0.
To get leads about my further steps I annotated Ogbe's publishing process [17] with my interpretations.
Ogbe uses xhtml for org export to html. In the hidden blog entry My Emacs Configuration [17] Ogbe offers structured insight into inspiring working space preparations; hidden because there's only a link from an “official” blog entry available from his menu item blog; and it is linked from other hidden and blog-listed entries. This hidden entry spreads into numerous Components, i.e., also hidden entries, like Org, Snippets, Completion, or References. And it contains an Exporting Section which explains [17]'s publishing process. The Section HTML Export in the hidden Org component offers offline export tweaks for local org html exports.
So, the most central information for my purpose of reconstructing
Ogbe's construction work is in the unhidden blog post Blogging
using org-mode [16]. I figured some features to act as
an elisp crash course for me. And for myself I marked
some which surpassed my rookie horizon. The folder structure for the
publishing lists blog-articles, blog-pages, and blog-rss is
summarized in Table 5. The different publishing actions are
org-html-publish-to-html for articles and pagesorg-rss-publish-to-rss for rss
org-publish-attachment for resources, images, and downloads.
The site contents are articles, pages, and hidden entries; the
resources are images, two css files, and plenty of
download files. Most of the download files are found in the News
Section of the home page. The alist entry of whole blog's publishing
components is
(setq org-publish-project-alist `(("blog" :components ( "blog-articles", "blog-pages", "blog-rss", "blog-res", "blog-images", "blog-dl"))
| articles | pages | rss | |
|---|---|---|---|
| :base-directory | blog/ | pages/ | blog/ |
| :publishing-directory | blog/ | . | . |
| :base-extension | "org" | "org" | "org" |
| :exclude | – | – | ".*" |
| :include | – | – | ("blog.org") |
| :html-link-up | "" | "" | |
| :html-link-home | "/", "" | "/", "" | "https://ogbe.net" |
| :html-link-use-abs-url | – | – | t |
Before getting into the article-page-sitemap production I shortly deal
with the files which are copied only; their common
:publishing-function is org-publish-attachment. The image and the
download folder 📂 img/ and 📂 dl/ are
copied recursively, the resources folder 📂 res/ employs
my-blog-minify-css; see Table 6.
| res | img | dl | |
|---|---|---|---|
| :base-directory | res/ | img/ | dl/ |
| :publishing-directory | res/ | img/ | dl/ |
| :base-extension | ".*" | ".*" | ".*" |
| :completion-function | my-blog-minify-css | ||
| :recursive | – | t | t |
my-blog-minify-css restructures all css files, i.e.,
📂 code.css and 📂 main.css at the
:publishing directory, with
csstidy --template=highest --silent=true
The elisp code is shown at length at the How to Blog.. [16] paragraph beginning with “The next preprocessor runs CSSTidy…”
The central rss constructor is org-rss-publish-to-rss
from the non-gnu 📂 ox-rss.el, while the
articles and the pages are made by
:publishing-function org-html-publish-to-html :htmlized-source t ;; this enables htmlize, which means that I can use ;; css for code!
:htmlized-source is a switch for exporting original org
files. The Section Publishing Action in the org Manual
says:
“If you want to publish the original org file with the archived, commented and tag-excluded trees removed, use the function
org-org-publish-to-org. This will produce 📂file.organd put it in the publishing directory. If you want a htmlized version of this file, set the parameter:htmlized-sourcetot; this will produce 📂file.org.htmlin the publishing directory.”
On the other hand enabling “htmlize, which means that I can use
css for code” is controlled by
org-html-htmlize-output-type and an integral part of every
org html export procedure, which is also used to
html'ize an original org file by
org-org-publish-to-org with :htmlized-source switched on. The
choices for org-html-htmlize-output-type are
css to export the css selectors onlyinline-css to export the css attribute values inline
in the HTML as <style> elementsnil to export plain text.
Both depend on the current buffer theme, which makes them
useless23 for batch mode exports and sensitive to collaborate
editing. org-html-htmlize-generate-css produces a buffer with all
current rich font definitions which we can use as a source for fixed
class definitions. But the intention of “I can use css
for code” still depends on the choice for
org-html-htmlize-output-type.
Define my-blog-extra-head as a string
(setq my-blog-extra-head (concat "<link rel='stylesheet' href='/../res/code.css' />\n" "<link rel='stylesheet' href='/../res/main.css' />"))
Both the blog-articles and the blog-pages publishing list contain
:html-link-home "/" :html-viewport nil :html-head nil :html-head-extra ,my-blog-extra-head :html-head-include-default-style nil :html-head-include-scripts nil
The :html-link-home property is set twice in Ogbe's script; further
down both link up and home are set to an empty string which means that
:html-link-up/home-format isn't included. afaik the
latter gets preference but I can't remember where I found that
statement.
The usage of the two properties :html-head and :html-head-extra:
is imho equivalent to
:html-head ,my-blog-extra-head
The property :html-head-include-scripts only regards the script
template org-html-scripts containing code highlighting functions,
i.e., “basic javascript that is needed by
html files produced by org mode.”24
Whatever that means, it doesn't apply to neither mathjax
nor Sebastian Rose's 📂 org-info.js enabled by
org-html-use-infojs; see the Manual's Section JavaScript supported
display of web pages or the worg entry Emacs org-info.js.
MathJax usually recommends to use their cdn to load their
javascript code; org supports this feature
by setting up the configuration template
org-html-mathjax-template. This template is fed by
org-html-mathjax-options or an in buffer setting like
#+HTML_MATHJAX: align: left indent: 5em tagside: left font: Neo-Euler
See the docstring of org-html-mathjax-options for detailed
explanations of the keywords and or the customization buffer for
accepted values. Ogbe's choice is to
use a local version and the configuration TeX-AMS-MML_HTMLorMML
instead of the org default TeX-AMS_HTML; see
Combined Configurations at docs.mathjax.org
(setq my-blog-local-mathjax '((path "/res/mj/MathJax.js?config=TeX-AMS-MML_HTMLorMML") (scale "100") (align "center") (indent "2em") (tagside "right") (mathml nil)))
and to feed it into his own template defined literally in blog-articles and
blog-pages publishing properties
:html-mathjax-options ,my-blog-local-mathjax :html-mathjax-template "<script type=\"text/javascript\" src=\"%PATH\"></script>"
Set my-blog-header-file and define the function my-blog-header to insert this file into the current buffer
(setq my-blog-header-file "~/repos/blog/header.html") (defun my-blog-header (arg) (with-temp-buffer (insert-file-contents my-blog-header-file) (buffer-string)))
According to the source code of the online files the content of my-blog-header-file 📂 header.html at 📂 ~/repos/blog/ is probably
<div id="preamble" class="status"> <header><div class="banner"> <a id="myname" href="/">Dennis Ogbe </a><hr> <nav><p><a href="/">Home</a> <a href="/about.html">About</a> <a href="/research.html">Research</a> <a href="/blog.html">Blog</a> </p></nav></div></header></div>
The footer contains the link to the rss file produced with the blog-rss publishing list and to a (missing) contact page. It's a string set with
(setq my-blog-footer "<hr />\n<p><span style=\"float: left;\"><a href= \"/blog.xml\">RSS</a></span>License: <a href= \"https://creativecommons.org/licenses/by-sa/4.0/\">CC BY-SA 4.0</a></p>\n<p><a href= \"/contact.html\"> Contact</a></p>\n")
In the publishing projects blog-articles and blog-pages the
function and the string are included with the project properties
:html-preamble my-blog-header :html-postamble ,my-blog-footer
So the preamble, i.e., header, is named my-blog-header and gets a
<header> element, while the postamble, i.e., footer, is named
my-blog-footer and goes without the privilege of a <footer>
element; see the <header> and the ARIA: banner role entries at
developer.mozilla.org about the intentions of these elements.
The html-link-home features are explained in the export script
📂 ox-html.el only. Unless :html-link-up and
:html-link-home are both "" the first entry after the <body>
element is created from :html-home/up-format; see the corresponding
doc-string.
<div id="org-div-home-and-up"> <a accesskey="h" href="%s"> UP </a> | <a accesskey="H" href="%s"> HOME </a> </div>
Both the blog-articles and the blog-pages publishing list contain
the confusing settings – because the link-home is defined twice –
:html-link-home "/" :html-home/up-format "" :html-link-up "" :html-link-home ""
while the blog-rss list defines
:html-link-home "https://ogbe.net/" :html-link-use-abs-url t
with an activated ..-use-abs-url setting which prepends relative
links with the content of the file based #+HTML_LINK_HOME: or the
publishing property :html-link-home.
According to the doc-string of org-html-footnotes-section the footnote section defaults to
<div id="footnotes"> <h2 class="footnotes">%s: </h2> <div id="text-footnotes"> %s </div> </div>
It should contain a two instances of %s.
Other settings are about
org-html-footnote-format which defaults to <sup>%s</sup>, where %s will be replaced by the footnote reference itselforg-html-footnote-separator set to <sup>, </sup>
Ogbe removes the language dependent part by defining :html-footnotes-section as
<div id='footnotes'><!--%s-->%s</div>
He also marks his superscript setting as !important without further explanation. This might be related to the footnotes.
:with-sub-superscript nil ;; important!!
But nil just means not to interpret the underscore "_" and the
caret "^" for export; see the doc-string of
org-export-with-sub-superscripts.
Ogbe says that his pre- and post-processors are used to move around some
files before and after publishing. Both my-blog-pages-postprocessor
and my-blog-articles-preprocessor are message dummies. The code is
shown at length at the How to Blog.. [16] paragraph
beginning with “Next I define some pre- and postprocessors…”
my-blog-pages-preprocessor moves a fresh version of the
📂 settings.org file to the pages directory. As I
understand the code it copies the current
📂 settings.org as my-blog-emacs-config-name, which
is set to 📂 emacsconfig.org, to destdir, containing
the value of :base-directory.my-blog-articles-postprocessor: “massage” the sitemap file and
move it up one directory. The “massage”-part is a comment further
down but not filled with a procedure: “massage the sitemap if
wanted”.
So, the whole function block seems only being concerned about moving
pages up. The inclusion at the blog-articles and blog-pages
publishing properties are four lines syntactically summarized to
:preparation-function my-blog-[articles|pages]-preprocessor :completion-function my-blog-[articles|pages]-postprocessor
The options for exporters Ogbe chooses to extract to his publishing configuration are discussed in Section 7. Here I focus on the two settings regarding org mode drawers.
:with-author t :with-creator nil :with-date t :headline-level 4 :section-numbers nil :with-toc nil :with-sub-superscript nil :with-drawers t :html-format-drawer-function my-blog-org-export-format-drawer
:with-drawers t enables the export of org mode drawers
and customizes the org-export-format-drawer-function with the
publishing property in the last line. Ogbe cites Panchekha
[19] for this idea. According to Panchenka's
Drawer Section Ogbe seems to dislike org mode's drawer
export-to-code-block default. The redefinition line at the end of
Panchekha's code example is equivalent to the publishing property
:html-format-drawer-function above. And the corresponding <div>
section generator is given as
(defun my-blog-org-export-format-drawer (name content) (concat "<div class=\"drawer " (downcase name) "\">\n" "<h6>" (capitalize name) "</h6>\n" content "\n</div>"))
The customizations that Ogbe “bolted” on org's publishing
features exceed my debugging skills. He built his own sitemap creator
added as project property :sitemap-function my-blog-sitemap in the
publishing list blog-articles written into :sitemap-filename
"blog.org". The function is also a part of
my-blog-articles-postprocessor which is employed as
:completion-function for both the blog-articles and the
blog-pages publishing list.25 The whole sitemap producing part of the
blog-articles publishing list is
;; sitemap - list of blog articles :auto-sitemap t :sitemap-filename "blog.org" :sitemap-title "Blog" ;; custom sitemap generator function :sitemap-function my-blog-sitemap :sitemap-sort-files anti-chronologically :sitemap-date-format "Published: %a %b %d %Y"
The purpose of the my-blog-sitemap specification is to include a
part of a blog entry as teaser in the his sitemap construction. Ogbe
encloses the “preview” part of the post in
#+BEGIN_PREVIEW...#+END_PREVIEW tags, which his “(very simple)
parser” then inserts into the sitemap page. The sitemap production is
connected to the publishing list blog-article. According to this
description the expanded sitemap production 📂 blog.html
is the central blog entry distributor for what I called unhidden
files.
The rss settings are addressed in a definition
(require 'ox-html) (require 'ox-rss) (setq org-export-html-coding-system 'utf-8-unix) (setq org-html-viewport nil)
and a publishing section
("blog-rss" :base-directory "~/repos/blog/blog/" :base-extension "org" :publishing-directory "~/repos/blog/www/" :publishing-function org-rss-publish-to-rss :html-link-home "https://ogbe.net/" :html-link-use-abs-url t :title "Dennis Ogbe" :rss-image-url "https://ogbe.loc/img/feed-icon-28x28.png" :section-numbers nil :exclude ".*" :include ("blog.org") :table-of-contents nil)
They fill the 📂 blog.org file which is
org-rss-publish-to-rss published to 📂 blog.xml. With
these informations and the 📂 ox-rss.el script I'm sure to
get some ideas about the rss export features.
Supplements of this posting: I provide the pdf here at pjs.netlify.app and a reduced version of the org source at bitbucket.org.
| [1] | Tim Berners-Lee and Mark Fischetti. Weaving the Web. HarperCollins, 2000. [ bib | .html ] |
| [2] | Steven Bird, Ewan Klein, and Edward Loper. Natural Language Processing with Python. O'Reilly Media, 2009. [ bib | http ] |
| [3] | Debra Cameron, James Elliott, Marc Loy, Eric Raymond, and Bill Rosenblatt. Learning GNU Emacs. O'Reilly Media, 3rd edition, 2004. [ bib | http ] |
| [4] | Steve Faulkner. On html belts and aria braces. URL, 2015. [ bib | http ] |
| [5] | Yuan Fu. Blog in org mode revisited. URL, 2018. [ bib | .html ] |
| [6] | Yuan Fu. Blog with only org mode. URL, 2018. [ bib | .html ] |
| [7] | Joshua Gay, editor. Free Software, Free Society. GNU Press, Free Software Foundation, 2015. [ bib | http ] |
| [8] | Glucksman Library. Cite it Right. University of Limerick’s Referencing Series. Glucksman Library, 2nd edition, 2008. [ bib ] |
| [9] | Kurt Hornik, Duncan Murdoch, and Achim Zeileis. Who did what? The R Journal, 4(1):64--69, June 2012. [ bib | http ] |
| [10] | Xah Lee. Emacs lisp: Call shell command. url, 2018. [ bib | .html ] |
| [11] | Eric A. Meyer and Estelle Weyl. CSS The Definitive Guide. o'Reilly, 2017. [ bib | http ] |
| [12] | Frank Mittelbach, Michel Goossens, Johannes L. Braams, David P. Carlisle, and Chris A. Rowley. The LaTeX Companion 2. Tools and Techniques for Computer Typesetting. Addison-Wesley Professional, Reading, Massachusetts, second edition, April 2004. [ bib ] |
| [13] | Peter Morville and Louis Rosenfeld. Information Architecture for the World Wide Web. O'Reilly, Beijing u.a., 3. ed. edition, 2006. [ bib | http ] |
| [14] | Simon Munzert, Christian Rubba, Peter Meißner, and Dominic Nyhuis. Automated Data Collection with R. Wiley John + Sons, 2014. [ bib | .html ] |
| [15] | Deborah Nolan and Duncan Temple Lang. XML and Web Technologies for Data Sciences with R. Use R! Springer New York, 2014. [ bib | DOI | http ] |
| [16] | Dennis Ogbe. Blogging using exclusively org-mode. URL, 2016. [ bib | .html ] |
| [17] | Dennis Ogbe. My emacs configuration. URL, 2020. [ bib | .html ] |
| [18] | Duncan Mac-Vicar P. Migrating from jekyll to org-mode and github actions. URL, 2019. [ bib | .html ] |
| [19] | Pavel Panchekha. Using org-mode to publish a web site. URL, 2011. [ bib | .html ] |
| [20] | pjs64. Org 2 shtml0 eazy. URL, 2022. [ bib | http ] |
| [21] | Sebastian Rose. Publishing treemenus for org-files. URL. [ bib | .html ] |
| [22] | Sebastian Rose. Publishing org-mode files to html. URL, 2020. [ bib | .html ] |
| [23] | Tessa Blakely Silver. Joomla! Template Design. packt publishing, Birmingham, 2007. [ bib ] |
| [24] | David Wood, Marsha Zaidman, Luke Ruth, and Michael Hausenblas. Linked Data. Manning, 2014. [ bib ] |
At first I only aim at switching off all javascript which is rendered superfluous with new ccs mechanics. Afterwards, but still not here, javascript and html api's are considered to be reinforced again.
Due to CSS: The Definite Guide [11], p.2, “it’s hard to speak of a single `css3 specification.' There isn’t any such thing, nor can there be.”
Another mandatory one
is :base-extension which defaults to org files; see
Selecting Files in the Manual. Expansion on this issue would lead directly
to a wide field of selective opportunities in the org
file construction or access to file parts.
My
motivation for turning to selfhtml is to reconstruct the information
architecture of the deprecated web technology site initiated by
Stephan Münz; see the mirror of version 8.0 at
www2.informatik.hu-berlin.de for example or look for the latest
version 8.1.2.
As a matter of fact, part of the motivation for scientific publication stems from mimicking an open source Scientific WorkPlace, beginning with the latex combination, abandoning the rstudio branded markdown temptation, and finally switching to the all inclusive org mode offer connected to gnu emacs and gnu linux.
It's available in the
bitbucket repository's folder 📂 supp. In
the long version it pretty soon moved into the – initially –
css producing org file, which currently
might be called the cms org file.
The <a
tabindex="0" aria-current="page"> markup for the current page
deviates from “plain”. It is discussed in the (German) quick-start
manual referring to a blog entry [4] at
html5doctor.com.
I began to call these escapes
directives for myself to separate them from #+begin container
constructs and to see them as parallel to C's preprocessor directives;
see the wikipedia entry directive (programming). But I'm
not sure if directive is a good choice.
Many desktops
intercept M-[TAB] to switch windows. Use C-M-i or [ESC] [TAB]
instead.
The <aside> is also used in the contacts page, but it's
shown like a section. Fixing this might be a proper exercise after
finishing this blog entry.
External info at the emacs-htmlize github page, elpa entry, or the entry at the emacs wiki.
This is the blueprint for something I might implement as an org mode agenda, but I first turned all the material I'm working on into a project file. I just can't find a way to put my thoughts into a get-things-done pattern. Talking of ill-structured? Here we go.
tikz is a parallel production of the beamer guy Tantau. tikz includes animation. A rapid slide show can be marked as the transition state to a motion picture. That's where I dare to compare tikz to svg.
For now I can only guess their usage. My work-around is to use R for all the programmatical purposes in a semi-manual deployment scenario. elisp intelligence postponed.
According to a 2019-04-20
discussion issue at bibeltex, referring to the
corresponding git commit entry at code.orgmode.org
📂 org-bibtex.el was renamed to
📂 ol-bibtex.el.
Examine
reftex-create-bibtex-file, 📂 reftex-cite.el or
📂 reftex.el or the reftex Manual.
Containing many org-bibtex-.. commands, but not part
of gnu emacs)
org version 9.5
texinfo offers
concept, function, key, #+PINDEX, #+TINDEX, and #+VINDEX,..
See
the Manual's Section and the doc-string of
org-export--prepare-file-contents.
Subsection 11.3.1 Programmatically Accessing a Blog, Section 11.3 Writing R Functions to Use XML-RPC in [15]'s Chapter 11 Simple Web Services and Remote Method Calls with XML-RPC.
This is my interpretation of the
org-html-htmlize-output-type doc-string. Not experimentally
verified.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}